OpenMP 基础 ¶
约 1894 个字 56 行代码 2 张图片 预计阅读时间 7 分钟
Abstract
超算小学期第七次课课程内容,第四次实验内容
参考:
OpenMP 简介 ¶
OpenMP 的适用范围:多线程、共享内存
- 共享存储体系结构上的一个并行编程模型
- 适用于 SMP(Symmetric Multi-Processor)共享内存多处理系统和多核处理器体系结构
三类主要 API(表现为编译制导指令,但实际上仍为 API
传统上,我们利用 OpenMP 进行单机器 CPU 优化(可跨处理器
OpenMP 编程模型 ¶
采用共享内存模型
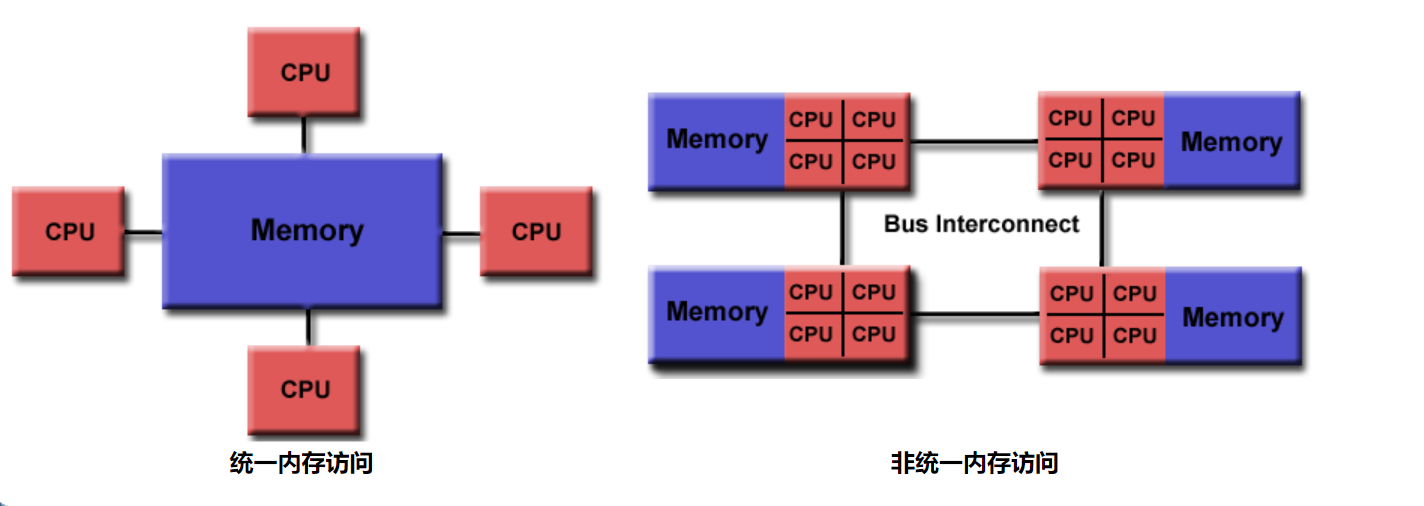
由于是共享内存架构,往往只能将 omp 应用在单节点上
HPC 中往往是四机集群的配置,不同机器之间通过 MPI 与 OMP 相结合实现分布式内存并行,混合并行编程
- OMP 用于在每个节点上进行计算密集型工作
- MPI 用于不同节点之间的通信和数据共享
并行性 ¶
几个概念:
- 进程:并发执行的程序在执行过程中分配和管理资源的基本单位(动态的
) ,作为竞争计算机系统资源的基本单位 - 线程:进程的一个执行单元(独立运行
) ,进程的内核调度实体(“轻量级进程”) - 协程:比线程更轻量级的存在,一个线程可以有多个协程(类似于不带返回值的子函数)
关于线程和进程:
- 进程之间地址空间为独立(CPU 保护模式
) ;线程之间共享本进程的地址空间(IO,CPU,内存亦如是) - 进程的程序入口执行开销大,当要进行频繁切换时,使用线程好于使用进程
- 由于地址空间等资源隔离,多进程时当一个进程挂掉并不会导致整个任务挂掉
- 如果要求同时进行并且又要共享某些变量的并发操作,只能用线程不能用进程
Fork-Join 模型 ¶
OpenMP 的并行只使用 Fork-Join 一种模型
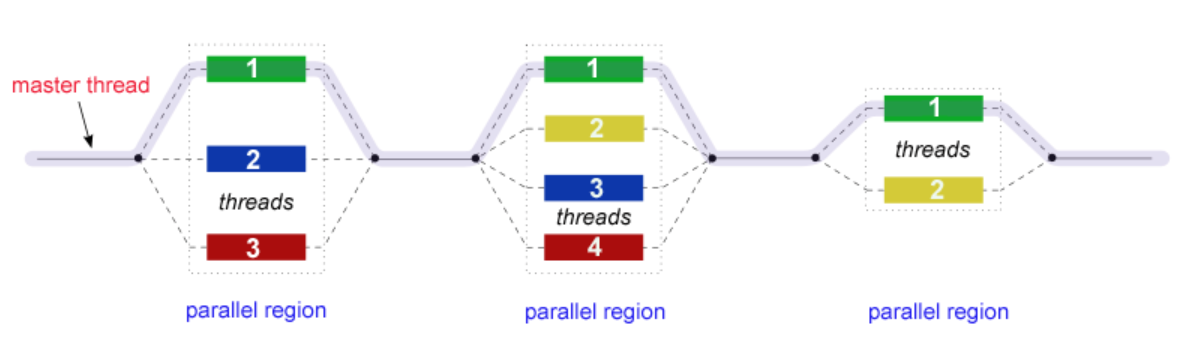
- OpenMP 程序开始于一个主线程,按照顺序执行,直到遇到第一个并行块
- fork:主线程创建一组并行线程
- join:当团队线程完成并行块中的语句时,它们将进行同步并终止,只留下主线程
- 并行块的数量和组成它们的线程是任意的
OpenMP API 简介 ¶
运行时函数库与环境变量 ¶
使用时要 #include <omp.h>,一些常用函数:
int omp_get_thread_num():获取当前线程号int omp_get_num_threads():获取总线程数double omp_get_wtime():获取时间,常用于计算线程内语句执行时间
OpenMP 会读取环境变量 OMP_NUM_THREADS 来决定创建的线程数
常见制导语句 ¶
也就是编译器指令,一些常用的:
#pragma omp parallel:创建并行块#pragma omp for:并行化 for 循环#pragma omp master:只有主线程执行#pragma omp single:仅有团队中一个线程执行#pragma omp sections:内部使用 section 指定不同线程运行的内容#pragma omp barrier:同步团队中所有线程#pragma omp atomic:原子方式访问内存
OpenMP 编程 ¶
线程并行 ¶
使用 #pragma omp parallel 创建并行块来并行运行同一段程序:
#include <omp.h>
#include <stdio.h>
#include <stdlib.h>
int main() {
#pragma omp parallel
{
int ID = omp_get_thread_num();
printf("thread #%d\n", ID);
}
}
- 运行时输出的顺序是不一定的
- #pragma 语句后面不能紧跟着大括号,一定要换一行
- 可以通过在 parallel 后面加 num_threads(xx) 来指定特定线程数
for 循环并行 ¶
parallel 块内可以使用 #pragma omp for 来对 for 循环进行并行,相当于将循环拆成不同部分分配给多个线程
- for 循环中不能包含 break(会报错
) ,且必须包含 "int i = xxx" - parallel 和 for 可以合起来写作一行
#pragma omp parallel for
条件并行 ¶
可以在制导语句后面加 if 子句来决定是否进行并行:
- 如果 x 不为 0 则分为四个线程执行块内内容
- 如果 x 为 0 则由主线程串行执行
sections 与 single ¶
sections 用于将工作拆分为若干部分,每部分分别由不同线程进行,实现“函数并行化”
#pragma omp parallel sections
{
#pragma omp section
printf("%d %d\n", omp_get_num_threads(), omp_get_thread_num());
#pragma omp section
printf("%d %d\n", omp_get_num_threads(), omp_get_thread_num());
}
- 此代码的两个 printf 将分到两个线程中分别执行
- 除非使用了 nowait,否则默认 sections 为 barrier(线程之间会互相等待)
single 用来序列化一段代码,即在一个进程中执行(处理非线程安全的代码,例如 IO)
任务调度 ¶
OpenMP 中任务调度主要用于并行的 for 循环,当循环中每次迭代的计算量不相等时,会造成某些线程空闲,没有使性能最大化
OpenMP 的任务调度方式有三种:static、dynamic、guide,使用 schedule 子句指定:
- static:默认情况,直接按照迭代次数分配
- dynamic:将任务分配到每个核心,有核心空闲了就接着分配。如果指定 size 为 2 就会每一次为每一个核心连续分配两个任务
- guided:采用指导性的启发式自调度方式。开始时每个线程会分配到较大的迭代块,之后分配到的迭代块会逐渐递减,按指数级下降到指定的 size 大小,没有指定 size 则会下降到 1
数据冒险 ¶
OpenMP 中每个线程都有自己的 Local Memory,但默认上并行块外的变量都是共享的,共享的存储在线程中同时读写时会出现问题
变量私有 ¶
可以利用 private 子句来声明 x 为每个线程私有的变量:
int x;
#pragma omp parallel for private(x)
for (int i = 0; i < 100; ++i) {
x = array[i];
array[i] = work(x);
}
- 此时对于 x 的访问就不会产生冲突
- 但在程序中应该假定每个线程内的 x 都没有被初始化(即每个线程中 x 最开始都是随机的)
- 也有 shared(x) 子句,这回使所有线程访问同一个地址空间
- x 也可以直接在并行块内声明
- 可以利用 firstprivate 和 lastprivate 子句来实现自动初始化
原子操作 ¶
- 多个线程在相近的时间段内对共享的变量进行更新,就会产生数据不一致的问题
- 原子操作可以保证更新操作不可再分
例如:
int counter = 0;
#pragma omp parallel num_threads(4) shared(counter)
{
for (int i = 0; i < 1000000; ++i) {
counter += 1;
}
}
在 counter += 1 一行上面加上 #pragma omp atomic 可以使这单个语句在汇编层面上原子化,也就相当于“加锁”了,这样就不会造成读写的冲突
reduction¶
reduction 子句为每个线程创建并私有化指定变量的私有副本,然后在并行结束之后将不同线程的结果合并为一个,例如:
int sum = 0;
#pragma omp parallel for reduction(+: sum)
for (int i = 0; i < 1000; ++i) {
sum += 1;
}
barrier¶
- 每个并行块都含有隐式的 barrier,也就是在所有线程都结束后才能继续向下运行
- 在并行块内也可以利用
#pragma omp barrier来同步各线程,即所有线程都触碰到 barrier 时再继续 - 可以利用 nowait 子句来取消并行块结尾的隐式 barrier,避免同步产生的开销