RISC-V 汇编实验 ¶
约 779 个字 129 行代码 1 张图片 预计阅读时间 4 分钟
Abstract
计算机系统 Ⅰ lab4-1 实验报告(2022.04.30 ~ 2022.05.13)
Warning
仅供学习参考,请勿抄袭
实验内容 ¶
- 实验 1
- 输入样例汇编,运行汇编
- 单步调试,给出每次 x1 数值变化的截图
- 回答 x7 最终的数值
- 实验 2
- 仿照样例程序,将学号 10 个数字依次写到 memory 地址 0x00040000 ~ 0x00040020 位置处
- 单步执行,对写入学号部分的效果截图
- 编写汇编程序,实现冒泡排序算法。要求从低地址到高地址,10 位学号的数字从大到小排序
- 单步执行程序,对每一轮扫描完成后的结果进行截图
- 给出汇编程序的源代码,并结合代码,重点说明两层循环的实现过程
- Bonus
- 修改上述程序,使得交换 memory 中两个数的位置的过程 swap 以函数调用的形式完成
实验 1 ¶
汇编代码 ¶
# riscv
initial:
lui x6, 0x666
addi x1, x0, 2
addi x2, x1, 14
sw x1, 8(x2)
l1:
ori x3, x1, 4
slli x1, x1, 4
lw x4, -8(x1)
srai x1, x1, 1
beq x1, x2, l2
addi x6, x6, -1
l2:
addi x1, x0, 2
bne x4, x1, l1
exit:
add x7, x2, x2
- lui x6 0x666:将 0x666 存至 x6 高 20 位
- addi x1, x0, 2:将 x0(0) 加立即数 2 存至 x1
- sw x1 8(x2):将 x1 存至 memory 中地址 x2 + 8 的位置
- ori x3, x1, 4:将 x1 与立即数按位或,存至 x3 中
- slli x1, x1, 4:将 x1 逻辑左移四位存入 x1 中
- lw x4, -8(x1):将 memory 中地址 x1 - 8 位置的值读到 x4 中
- srai x1, x1, 1:将 x1 逻辑右移 1 位存入 x1 中
- beq x1, x2, l2:若 x1 == x2 则跳到标号 l2 处
- bne x4, x1, l1:若 x4 != x1 则跳到标号 l1 处
x1 变化截图 ¶
将单步运行时 x1 寄存器的值拼接了起来
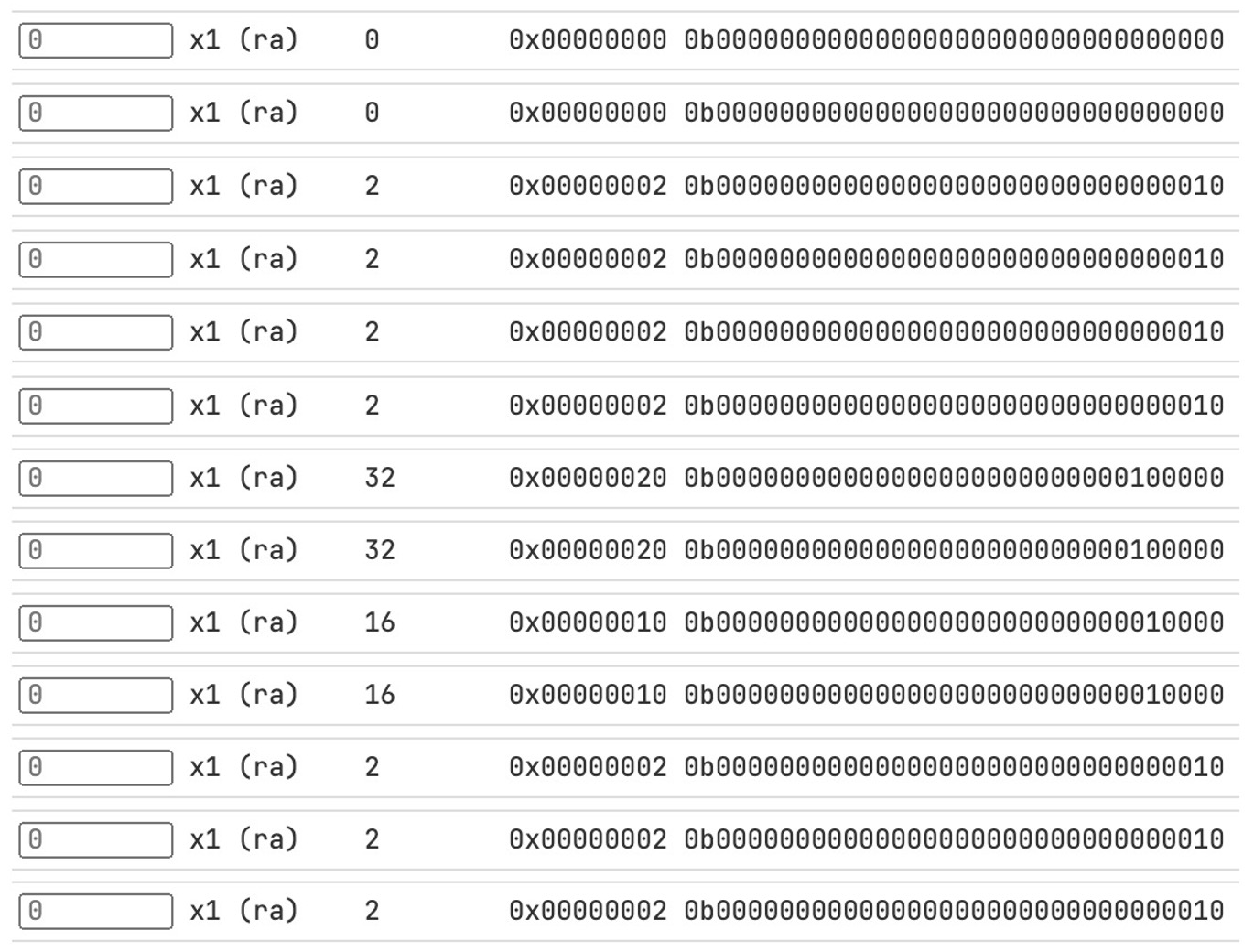
x7 最终值为 32
实验 2 ¶
写入学号 ¶
仿照样例
addi x5, x0, 3
addi x6, x0, 0
lui x6, 0x40
sw x5, 0(x6)
addi x5, x0, 2
sw x5, 4(x6)
addi x5, x0, 1
sw x5, 8(x6)
addi x5, x0, 1
...
冒泡排序 ¶
# 接上面代码
addi x5, x0, 40 # len
addi t3, x0, 0 # i
for1:
addi t4, x0, 0 # j
for2:
add x7, x6, t4
lw t5, 0(x7)
lw t6, 4(x7)
bge t5, t6, for2_end
sw t5, 4(x7)
sw t6, 0(x7)
for2_end:
addi t4, t4, 4
addi t6, x0, 4
sub t5, x5, t6
sub t5, t5, t3
blt t4, t5, for2
for1_end:
addi t3, t3, 4
addi t6, x0, 4
sub t5, x5, t6
blt t3, t5, for1
每轮冒泡的结果 ¶
(隐私问题,不展示)
最后一次就是排好序后的结果
Bonus¶
由于提供的 interpreter 不支持一般的函数操作,所以使用 sp 指针模拟栈、jal 指针手动跳转来模拟函数行为
swap 函数(从栈上取两个数,交换再放回去
swap:
addi sp, sp, -4
lw a0, 0(sp)
addi sp, sp, -4
lw a1, 0(sp)
add a2, x0, a1
add a1, x0, a0
add a0, x0, a2
sw a1, 0(sp)
addi sp, sp, 4
sw a0, 0(sp)
addi sp, sp, 4
jal x0, swap_exit
完整代码:
addi x5, x0, 3
addi x6, x0, 0
lui x6, 0x40
sw x5, 0(x6)
addi x5, x0, 2
sw x5, 4(x6)
addi x5, x0, 1
sw x5, 8(x6)
addi x5, x0, 1
sw x5, 0x10(x6)
...
addi sp, x0, 0
lui sp, 0x80
addi x5, x0, 40 # len
addi t3, x0, 0 # i
for1:
addi t4, x0, 0 # j
for2:
add x7, x6, t4
lw t5, 0(x7)
lw t6, 4(x7)
bge t5, t6, for2_end
sw t5, 0(sp)
addi sp, sp, 4
sw t6, 0(sp)
addi sp, sp, 4
jal x0, swap
swap_exit:
addi sp, sp, -4
lw t6, 0(sp)
addi sp, sp, -4
lw t5, 0(sp)
sw t5, 0(x7)
sw t6, 4(x7)
for2_end:
addi t4, t4, 4
addi t6, x0, 4
sub t5, x5, t6
sub t5, t5, t3
blt t4, t5, for2
for1_end:
addi t3, t3, 4
addi t6, x0, 4
sub t5, x5, t6
blt t3, t5, for1
jal x0, exit
swap:
addi sp, sp, -4
lw a0, 0(sp)
addi sp, sp, -4
lw a1, 0(sp)
add a2, x0, a1
add a1, x0, a0
add a0, x0, a2
sw a1, 0(sp)
addi sp, sp, 4
sw a0, 0(sp)
addi sp, sp, 4
jal x0, swap_exit
exit:
addi x0, x0, 0
经单步运行测试,结果与原来一致。