流水线 CPU 设计 ¶
约 2965 个字 180 行代码 9 张图片 预计阅读时间 12 分钟
Abstract
计算机系统 Ⅱ lab1 实验报告(2022.09.22 ~ 2022.10.13)
Warning
仅供学习参考,请勿抄袭
实验内容 ¶
- lab 1-1:流水线加法机
- 基于 lab 0 的单周期 CPU 搭建流水线加法机,支持 addi 和 nop 指令
- 进行仿真测试,检验 CPU 基本功能
- 进行上板测试,检验 CPU 设计规范
- 思考题
- 对于 part1 (2-14 行 ),请计算你的 CPU 的 CPI,再用 lab0 的单周期 CPU 运行 part1,对比二者的 CPI
- 对于 part2 (24-39 行 ),请计算你的 CPU 的 CPI(假设 nop 不计入指令条数
) ,再用 lab0 的单周期 CPU 运行 part2,对比二者的 CPI。试解释为何需要添加 nop 指令
- lab 1-2:指令扩展
- 基于 lab 1-1,在流水线 CPU 中实现 lui、jal、jalr、beq、bne、lw、sw、addi、slti、xori、ori、andi、srli、srai、add、sub、sll、slt、sra、or、xor、and 指令
- 搭建完整的流水线 CPU
- 进行仿真测试和上板测试
- 思考题
- 在你的设计中,本实验测试文件中的 nop 数量是否多于每条指令所需的延迟周期数
- 又是否存在出现冲突但是没有给足 nop 的情况
- 请计算每条指令间实际所需要的 nop 数量,并对你的 coe 文件进行修改,使之正确地运行出相应的结果
流水线加法机 ¶
数据通路设计 ¶
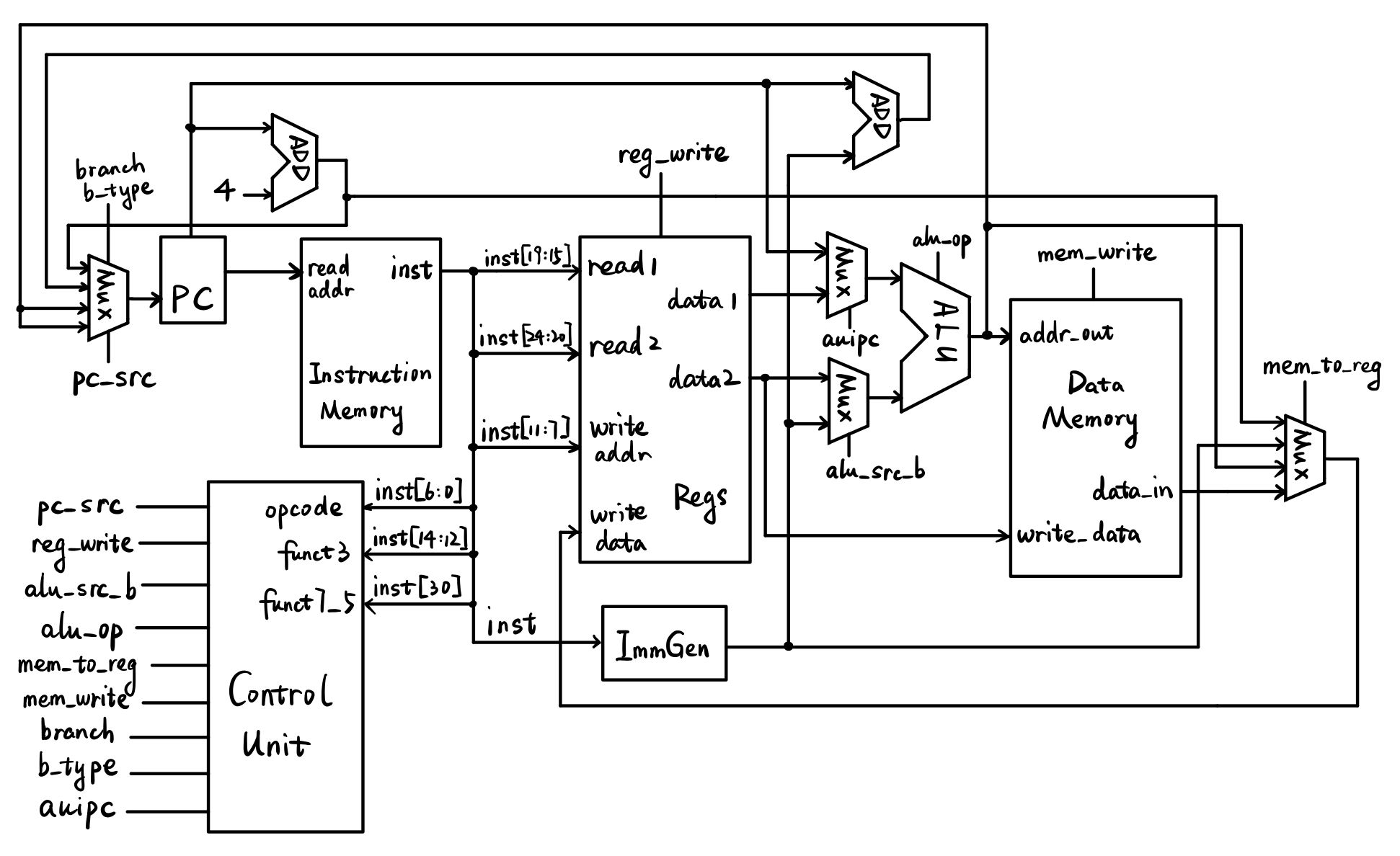
之前的单周期 CPU 数据通路设计(因为添加了 auipc 指令,所以和上课讲的有些许不一样
nop 指令编译后相当于 addi x0, x0, 0,所以即只存在 addi 指令。在设计数据通路时可以先简化一下,不考虑 pc 的跳转变化,直接在 IF 阶段不断加四即可。所以在单周期 CPU 数据通路的基础上再加上四个阶段寄存器来分割即可(很多其它指令的细节也进行了保留,但在这部分中不会用到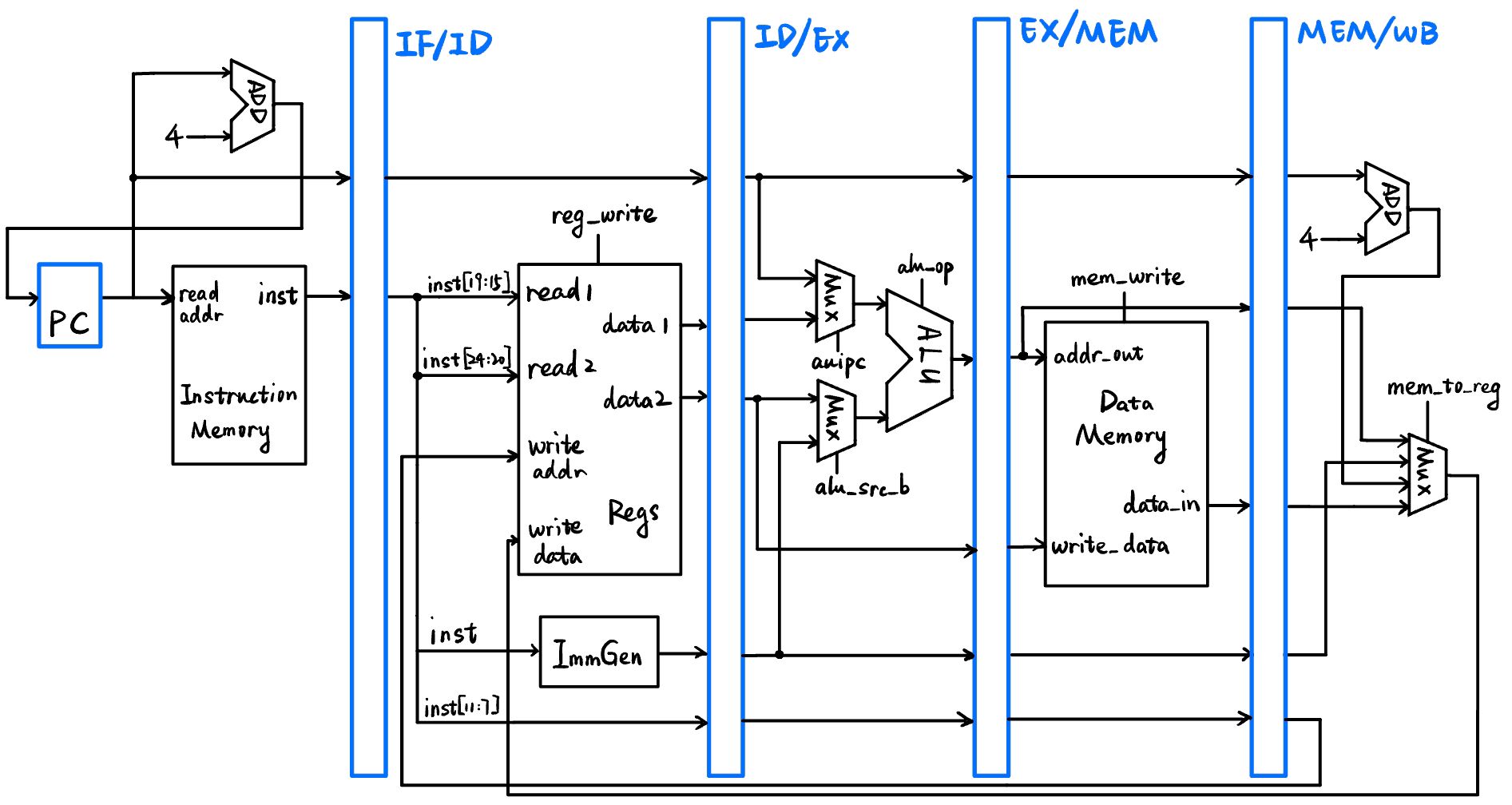
代码编写 ¶
由于本次实验不对数据通路进行封装,所以直接在 SCPU 中进行上述设计的实现。
IF 段 ¶
IF 段是由 PC 和 IF/ID 两个寄存器(时序电路)分隔的。其中从 I-Mem 读取指令的部分在 SCPU 之外,也就是通过 pc_out 传出当前 pc,然后得到指令通过 inst 返回到 SCPU 中。因为 Core 中为 ROM 设置的 clk 与 SCPU 正好错位,所以可以在 IF 所在的时钟周期中直接完成指令的读取。
体现在代码上即在上升沿时更新 pc 为 pc_next(pc+4
wire [31:0] pc_next;
reg [31:0] pc;
reg [31:0] IF_ID_pc;
reg [31:0] IF_ID_inst;
assign pc_out = pc;
assign pc_next = pc + 4; // 不考虑跳转
always @(posedge clk or posedge rst) begin
if (rst) begin
pc <= 32'b0;
IF_ID_pc <= 32'b0;
end
else begin
pc <= pc_next;
IF_ID_pc <= pc;
IF_ID_inst <= inst;
end
end
ID 段 ¶
ID 阶段需要进行寄存器组的访问、立即数生成以及指令译码,从数据通路图上可以看出,除了控制信号以外,输出给 ID/EX 寄存器的值有 pc、data1、data2、imm、write_addr。控制信号有 pc_src、mem_to_reg、reg_write、alu_src、branch、b_type、auipc、mem_write。所以需要根据这些来创建 ID/EX 寄存器,附带中间需要用到的 wire,代码为:
wire [31:0] read_data1, read_data2, imm;
wire [3:0] alu_op;
wire [1:0] pc_src, mem_to_reg;
wire reg_write, alu_src, branch, b_type, auipc, mem_write_;
reg [31:0] ID_EX_data1, ID_EX_data2;
reg [31:0] ID_EX_pc, ID_EX_imm;
reg [4:0] ID_EX_write_addr;
reg [3:0] ID_EX_alu_op;
reg [1:0] ID_EX_pc_src, ID_EX_mem_to_reg;
reg ID_EX_reg_write, ID_EX_alu_src, ID_EX_branch, ID_EX_b_type, ID_EX_auipc, ID_EX_mem_write;
ID_EX_pc <= IF_ID_pc;
ID_EX_data1 <= read_data1;
ID_EX_data2 <= read_data2;
ID_EX_imm <= imm;
ID_EX_write_addr <= IF_ID_inst[11:7];
ID_EX_pc_src <= pc_src;
ID_EX_mem_to_reg <= mem_to_reg;
ID_EX_reg_write <= reg_write;
ID_EX_alu_src <= alu_src;
ID_EX_branch <= branch;
ID_EX_b_type <= b_type;
ID_EX_auipc <= auipc;
ID_EX_alu_op <= alu_op;
ID_EX_mem_write <= mem_write_;
Regs regs (
.clk(clk),
.rst(rst),
.we(____), // 留给 WB 阶段
.read_addr_1(IF_ID_inst[19:15]),
.read_addr_2(IF_ID_inst[24:20]),
.write_addr(____), // 留给 WB 阶段
.write_data(____), // 留给 WB 阶段
.read_data_1(read_data1),
.read_data_2(read_data2)
);
Control control (
.op_code(IF_ID_inst[6:0]),
.funct3(IF_ID_inst[14:12]),
.funct7_5(IF_ID_inst[30]),
.alu_op(alu_op),
.pc_src(pc_src),
.mem_to_reg(mem_to_reg),
.reg_write(reg_write),
.alu_src_b(alu_src),
.branch(branch),
.b_type(b_type),
.mem_write(mem_write_),
.auipc(auipc)
);
ImmGen immgen (
.inst(IF_ID_inst),
.imm(imm)
);
EX 段 ¶
EX 阶段主要进行 ALU 运算,根据数据通路图可以看出,此阶段的输出(也就是 EX/MEM 寄存器中需要存的值)有 pc、alu_result、data2、imm、write_addr。控制信号在这一阶段中使用掉了 alu_op、alu_src_b 和 auipc,其余的还需要继续通过 EX/MEM 寄存器传下去。因此 EX/MEM 寄存器以及其它中间 wire 的定义:
wire [31:0] alu_data1, alu_data2, alu_result;
wire alu_zero;
reg [31:0] EX_MEM_alu_result, EX_MEM_pc, EX_MEM_imm;
reg [31:0] EX_MEM_data2;
reg [4:0] EX_MEM_write_addr;
reg [1:0] EX_MEM_pc_src, EX_MEM_mem_to_reg;
reg EX_MEM_reg_write, EX_MEM_branch, EX_MEM_b_type, EX_MEM_mem_write;
EX_MEM_pc <= ID_EX_pc;
EX_MEM_imm <= ID_EX_imm;
EX_MEM_data2 <= ID_EX_data2;
EX_MEM_alu_result <= alu_result;
EX_MEM_write_addr <= ID_EX_write_addr;
EX_MEM_pc_src <= ID_EX_pc_src;
EX_MEM_mem_to_reg <= ID_EX_mem_to_reg;
EX_MEM_reg_write <= ID_EX_reg_write;
EX_MEM_branch <= ID_EX_branch;
EX_MEM_b_type <= ID_EX_b_type;
EX_MEM_mem_write <= ID_EX_mem_write;
Mux2x32 mux2x32_1 (
.I0(ID_EX_data1),
.I1(ID_EX_pc),
.s(ID_EX_auipc),
.o(alu_data1)
);
Mux2x32 mux2x32_2 (
.I0(ID_EX_data2),
.I1(ID_EX_imm),
.s(ID_EX_alu_src),
.o(alu_data2)
);
ALU alu (
.a(alu_data1),
.b(alu_data2),
.alu_op(ID_EX_alu_op),
.res(alu_result),
.zero(alu_zero) // 其实我没用
);
MEM 段 ¶
MEM 阶段需要进行 D-Mem 的访问,虽然 addi 指令不会涉及到 MEM 阶段,但是在此也进行了这一部分实现。D-Mem 也定义在 SCPU 之外,需要通过 SCPU 的接口来进行访问,即通过 addr_out 这一输出来输入给 RAM 指定操作的地址,data_out 输出来输入给 RAM 指定写入的数据,输出 mem_write 控制信号来指定进行写入还是读取,以及 RAM 输出 data_in 给 SCPU 作为读取的数据。所以 SCPU 中只需要 assign 连线即可:
assign addr_out = EX_MEM_alu_result;
assign data_out = EX_MEM_data2;
assign mem_write = EX_MEM_mem_write;
下一步是进行 MEM/WB 寄存器的写入。从数据通路图中可以看出,需要写入的数据有 pc、alu_result、data_in、imm、write_addr。这一阶段的控制信号用掉了 mem_write,但是后续的跳转计算也计划在这里完成,将消耗 branch、b_type、pc_src 三个信号,最后 WB 阶段中会使用到的也只剩下 mem_to_reg 和 reg_write 两个了。因此寄存器定义:
reg [31:0] MEM_WB_data_in, MEM_WB_alu_result, MEM_WB_pc, MEM_WB_imm;
reg [4:0] MEM_WB_write_addr;
reg [1:0] MEM_WB_mem_to_reg;
reg MEM_WB_reg_write;
MEM_WB_data_in <= data_in;
MEM_WB_alu_result <= EX_MEM_alu_result;
MEM_WB_pc <= EX_MEM_pc;
MEM_WB_imm <= EX_MEM_imm;
MEM_WB_write_addr <= EX_MEM_write_addr;
MEM_WB_mem_to_reg <= EX_MEM_mem_to_reg;
MEM_WB_reg_write <= EX_MEM_reg_write;
WB 段 ¶
WB 段进行寄存器组的写回操作,需要复用 ID 阶段中定义连接的 Regs 模块,也就是先选择出需要写回的数据 write_data,然后写回在 write_addr 地址处的寄存器。因此需要一个 wire 变量 write_data。不需要再定义额外的寄存器。
对于 write_data 的选择,其来源有四个(完整情况下
Mux4x32 mux4x32 (
.I0(MEM_WB_alu_result),
.I1(MEM_WB_imm),
.I2(MEM_WB_pc + 4),
.I3(MEM_WB_data_in),
.s(MEM_WB_mem_to_reg),
.o(write_data)
);
Regs regs (
...
.we(MEM_WB_reg_write),
...
.write_addr(MEM_WB_write_addr),
.write_data(write_data),
...
);
仿真测试 ¶
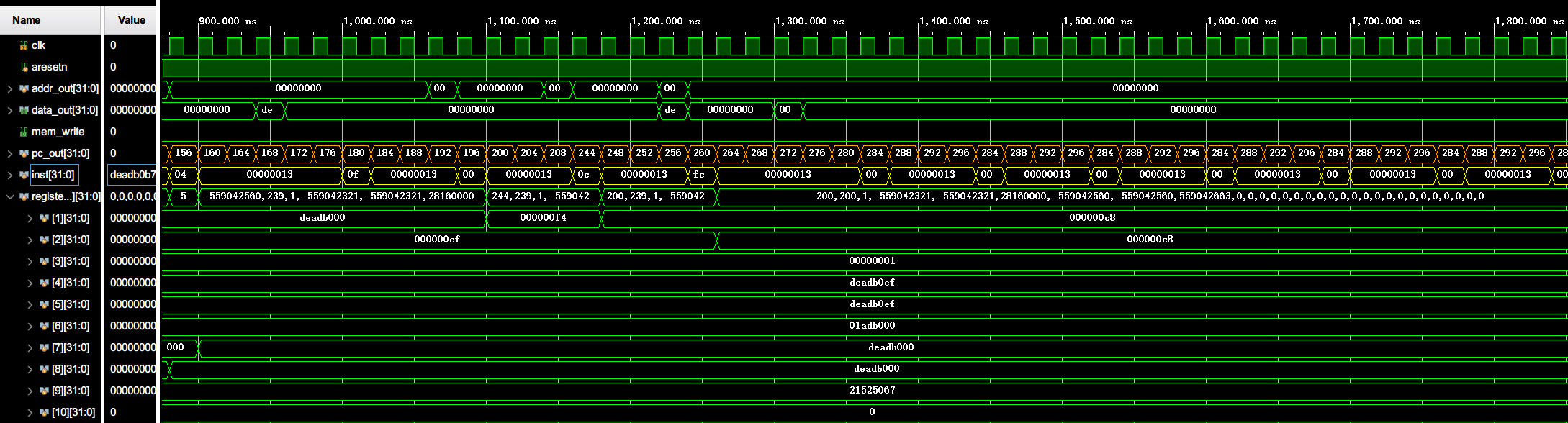
按照之前的指导,将 lab1-1.coe 载入 ROM 中,然后以 Core_tb 为顶层模块进行仿真测试,仿真结果波形如下(包含 SCPU 中的 clk 信号、pc、inst 以及寄存器的变化
对于这个波形的分析如下图(黑色、橙色方块为 addi 指令,红色方块为 nop 指令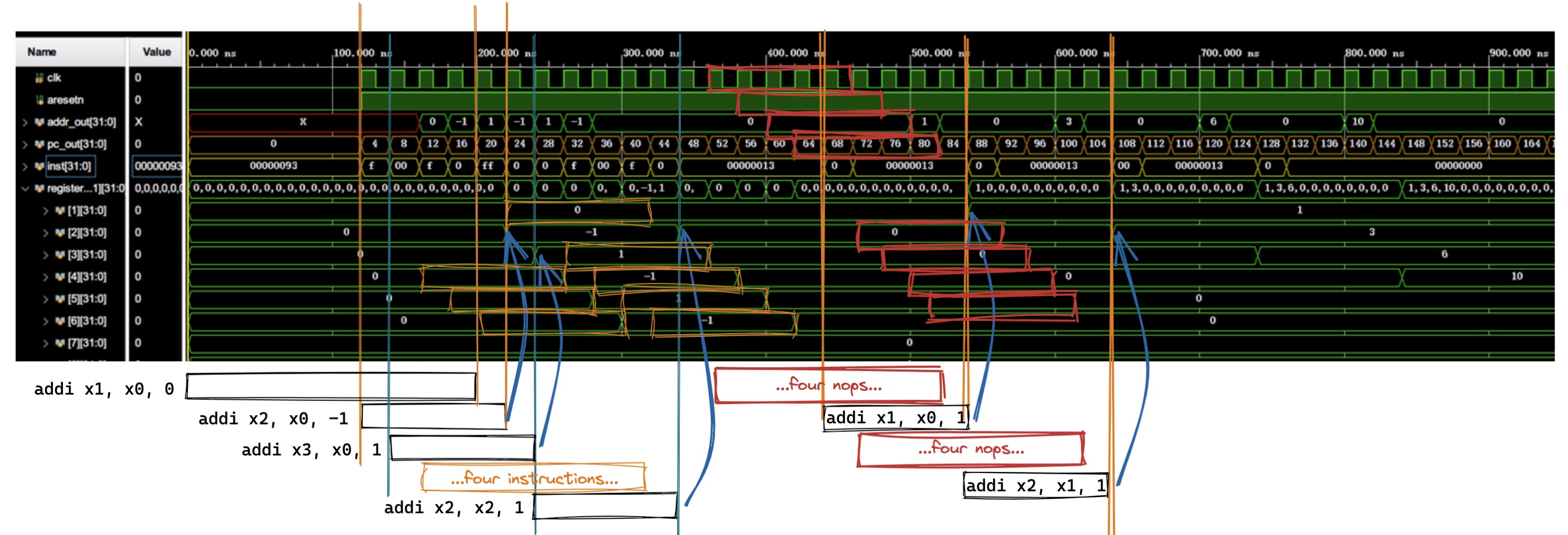
可以发现,指令确实叠在一起运行,一条指令运行五个周期,同一周期内运行五条指令,形成一个五阶流水线,且寄存器中结果变化均符合预期(在最后一个阶段 WB 写回产生变化,且值与汇编语句中描述相同)
思考题 ¶
- 对于 part1 (2-14 行 ),请计算你的 CPU 的 CPI,再用 lab0 的单周期 CPU 运行 part1,对比二者的 CPI
- 对于 part2 (24-39 行 ),请计算你的 CPU 的 CPI(假设 nop 不计入指令条数
) ,再用 lab0 的单周期 CPU 运行 part2,对比二者的 CPI。试解释为何需要添加 nop 指令
完整流水线 CPU ¶
数据通路 ¶
在前面的简化数据通路基础上进行更改,需要修改的仅是为 pc 赋值的部分。采用了和 lab0 中相同的用于 pc 的多路选择器,其结构为:
input [31:0] I0, // pc+4
input [31:0] I1, // jalr 的地址
input [31:0] I2, // jal 的地址
input [31:0] I3, // branch 的地址,和 jal 相同
input [1:0] s, // pc_src 控制信号
input branch, // branch 控制信号(是否是 branch 语句)
input b_type, // b_type 控制信号(0 表示 bne,反之 beq)
input [31:0] alu_res, // alu 的结果(作用相当于 alu_zero)
output [31:0] o // pc_next
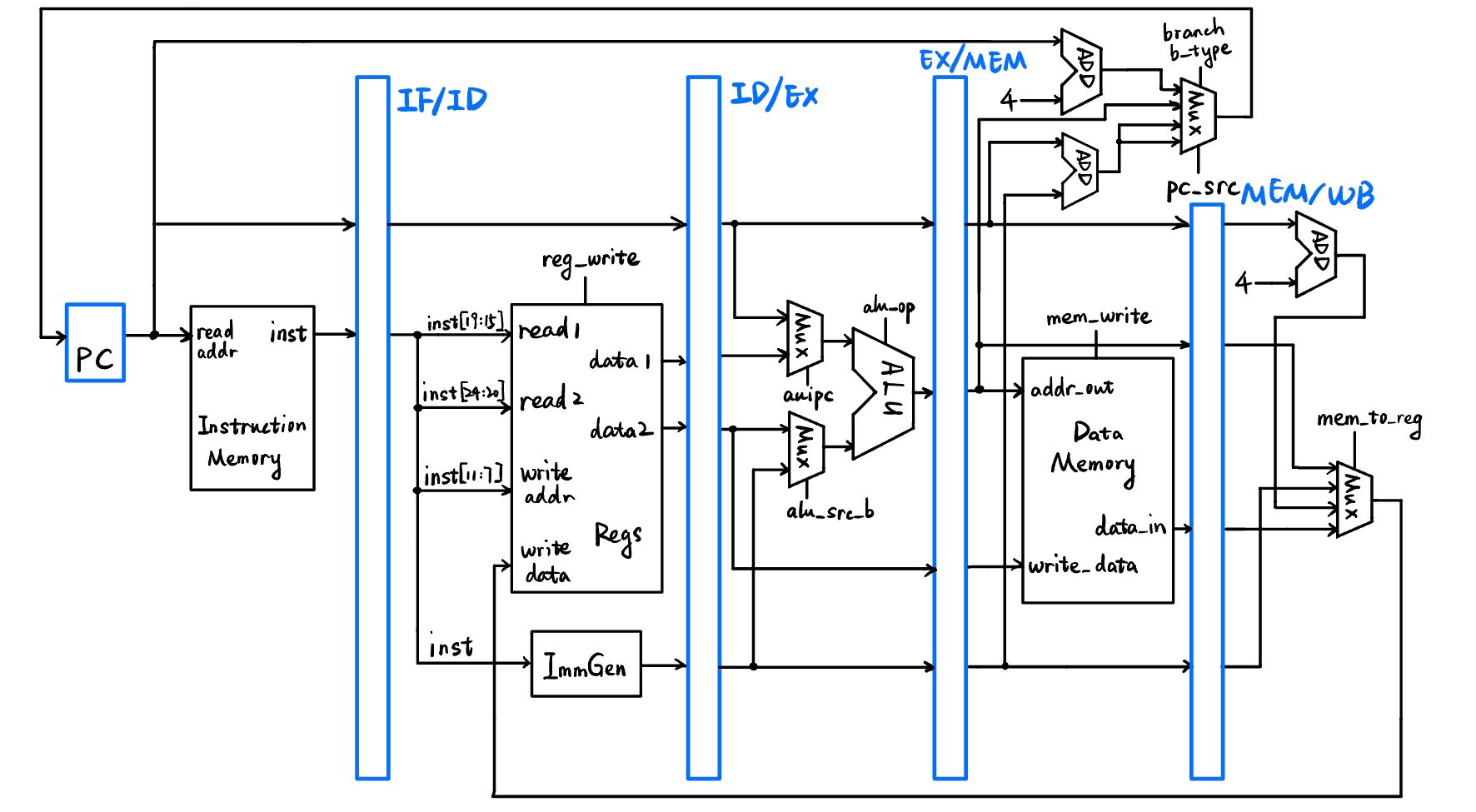
代码实现 ¶
首先需要删掉前面写的 assign pc_next = pc+4; 然后增加创建并连接 MuxPC 模块:
wire [31:0] jal_addr, jalr_addr;
//--------------------MEM--------------------//
assign addr_out = EX_MEM_alu_result;
assign data_out = EX_MEM_data2;
assign mem_write = EX_MEM_mem_write;
assign jal_addr = EX_MEM_pc + EX_MEM_imm;
assign jalr_addr = EX_MEM_alu_result;
MuxPC mux_pc (
.I0(pc + 4),
.I1(jalr_addr),
.I2(jal_addr),
.I3(jal_addr),
.s(EX_MEM_pc_src),
.branch(EX_MEM_branch),
.b_type(EX_MEM_b_type),
.alu_res(EX_MEM_alu_result),
.o(pc_next)
);
仿真测试 ¶
因为在 lab0 中已经完成了 bonus 指令,包含了本实验中的所有指令,所以直接载入 coe 文件运行即可,仿真波形如下:

波形分析 ¶
第一部分,正常运行了一些计算指令,结果均正确。并且几个 bne 跳转未达到条件没有跳转。
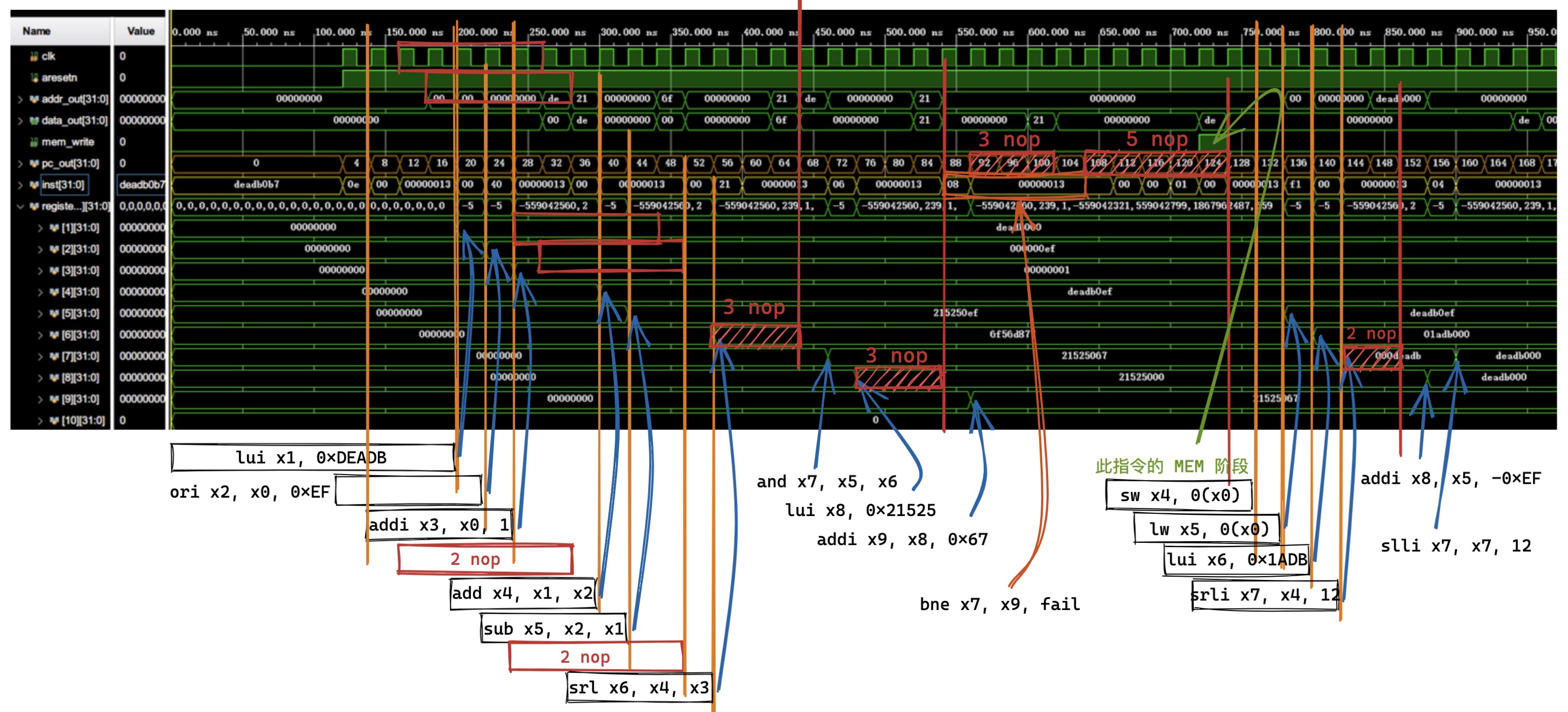
第二部分,主要是跳转,slli 指令后面接三个 nop,然后是 jalr 无条件跳转指令,其中 MEM 阶段后更改了 pc,WB 阶段后将该指令 pc 加 4 后存入了 x1 寄存器中。然后是一些 nop 指令防止副作用(此处只执行了三个
通过以上分析,可见运行是正确的。
上板验证 ¶
需要修改一个地方用来 debug,即将 SCPU 的 debug_reg_addr 输入到 Regs 中,然后输出 debug_reg,传入上级 Core 中,来查看某一寄存器的值。
其它功能(看 pc、addr_out、inst,以及根据开关设置 debug_reg_addr)已经在 lab0 中实现,这里保留即可。
上板后逐周期调试运行,均和波形一致,结果正确。
思考题 ¶
- 在你的设计中,本实验测试文件中的 nop 数量是否多于每条指令所需的延迟周期数?
- 又是否存在出现冲突但是没有给足 nop 的情况?
- 请计算每条指令间实际所需要的 nop 数量,并对你的 coe 文件进行修改,使之正确地运行出相应的结果