Unicode 统一码 ¶
约 2502 个字 9 张图片 预计阅读时间 8 分钟
Unicode(别名 Universal coded character set (UCS)
) ,官方中文名称为统一码,是计算机科学领域的业界标准。它整理、编码了世界上大部分的文字系统,使得电脑可以用更为简单的方式来呈现和处理文字。Unicode 伴随着通用字符集的标准而发展,同时也以书本的形式对外发表。Unicode 至今仍在不断增修,每个新版本都加入更多新的字符。目前最新的版本为 2021 年 9 月公布的 14.0.0,已经收录超过 14 万个字符(第十万个字符在 2005 年获采纳
) 。Unicode 除了视觉上的字形、编码方法、标准的字符编码资料外,还包含了字符特性(如大小写字母) 、书写方向、拆分标准等特性的资料库。———— 维基百科
Abstract
一直觉得 Unicode 和 UTF-8 编码很有意思,就看了看
Unicode 字符集 ¶
Unicode 的字符集以分组的形式进行编排,整体分为 17 个平面(Plane)


每个平面中有 \(2^{16}\) 个码位(codepoint
Unicode 字符集中每个字符都有一个编号,即字符值。化为十六进制后后四位为在当前平面上的码值,前面剩余的为平面编号
比如 "鹤" 这个字符的字符值是 0x9E64,表示为 U+9E64
字符平面映射 ¶
| 平面编号 | 字符值范围 | 名称 |
|---|---|---|
| 0 | U+0000 ~ U+FFFF | BMP(Basic Multilingual Plane)基本多文种平面 |
| 1 | U+10000 ~ U+1FFFF | SMP(Supplementary Multilingual Plane)多文种补充平面 |
| 2 | U+20000 ~ U+2FFFF | SIP(Supplementary Ideographic Plane)表意文字补充平面 |
| 3 | U+30000 ~ U+3FFFF | TIP(Tertiary Ideographic Plane)表意文字第三平面 |
| 4~13 | U+40000 ~ U+DFFFF | Reserved Planes 尚未使用 |
| 14 | U+E0000 ~ U+EFFFF | SSP(Supplementary Special-purpose Plane)特别用途补充平面 |
| 15 | U+F0000 ~ U+FFFFF | PUA-A(Private Use Area-A)私人使用区 A 区 |
| 16 | U+100000 ~ U+10FFFF | PUA-B(Private Use Area-B)私人使用区 B 区 |
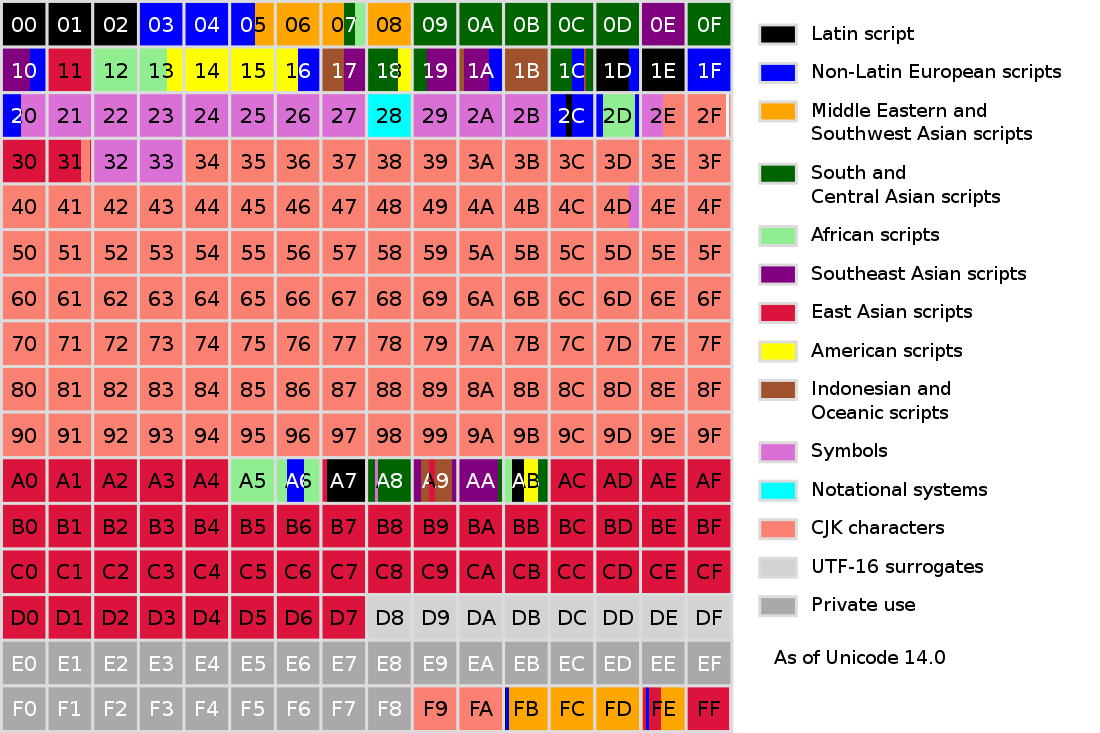
SMP 平面(第一辅助平面)
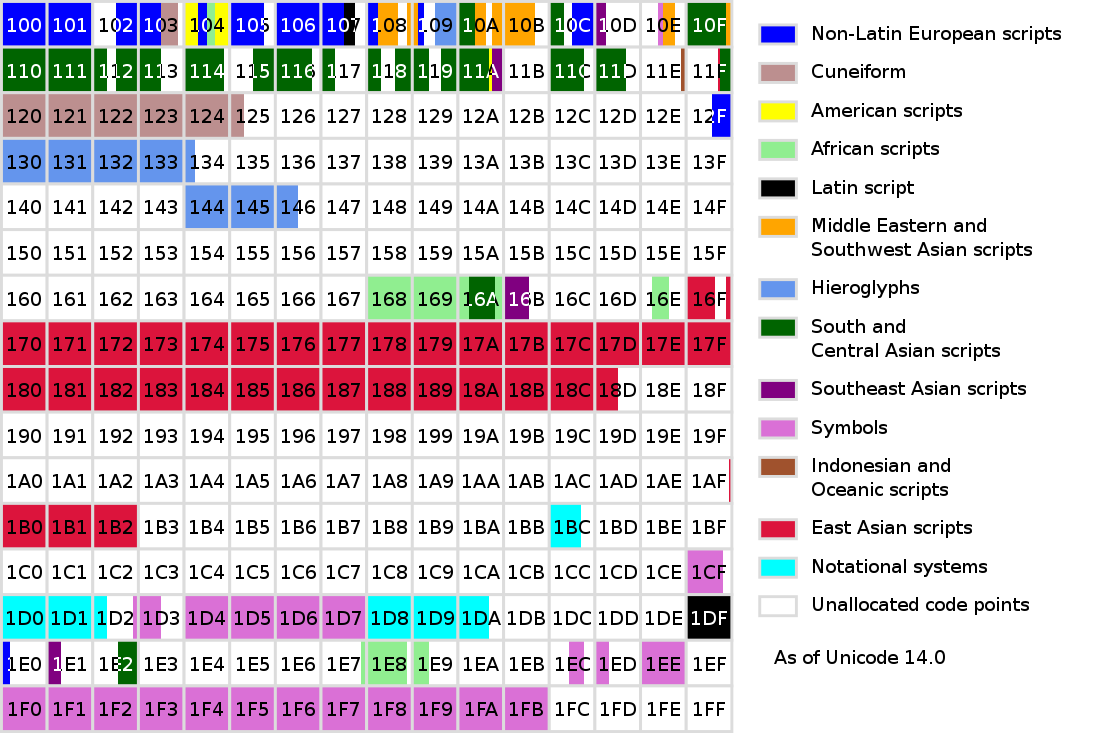 主要摆放绝大多数古代文字,现时已不再使用或很少使用文字、速记、数学字母符号、音符、图形符号及用于学者的专业论文中使用的古老或过时的语言书写符号,以及 emoji
主要摆放绝大多数古代文字,现时已不再使用或很少使用文字、速记、数学字母符号、音符、图形符号及用于学者的专业论文中使用的古老或过时的语言书写符号,以及 emoji
详见:
SIP 平面(第二辅助平面)
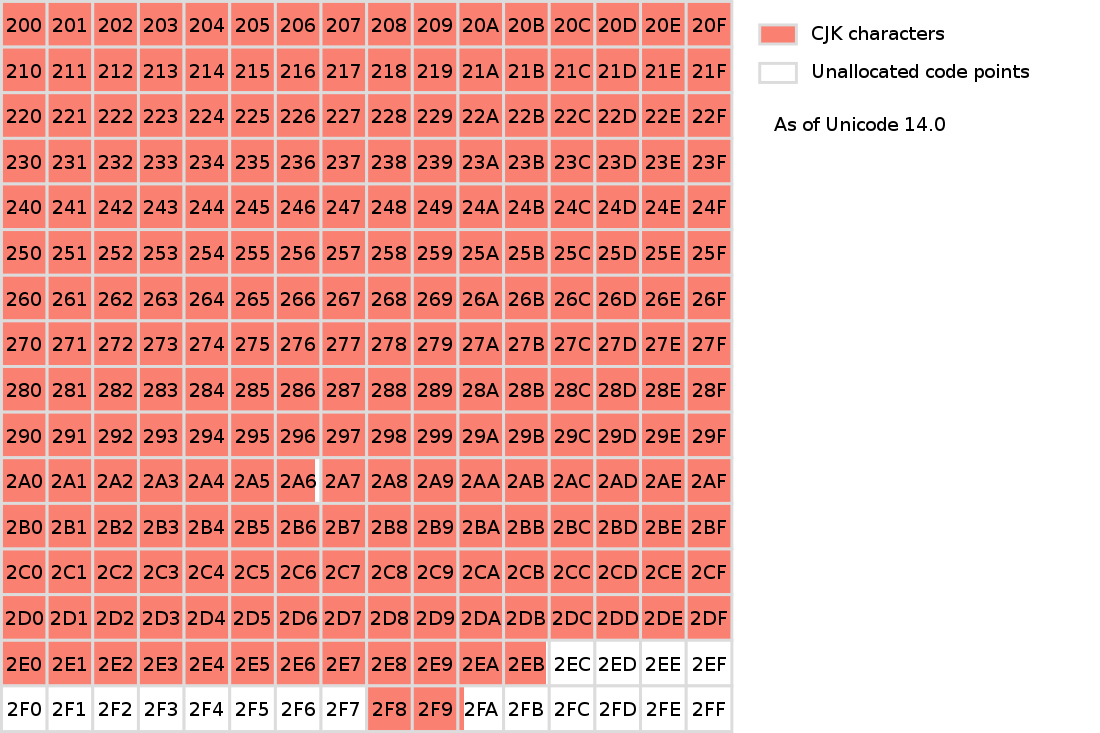 全为 CJK 字符,包含少用的汉字以及某些方言文字
全为 CJK 字符,包含少用的汉字以及某些方言文字
- U+20000 ~ U+2A6DF:中日韩统一表意文字扩展 B 区(CJK Unified Ideographs Extension B)43253 个汉字
- U+2A700 ~ U+2B73F:中日韩统一表意文字扩展 C 区(CJK Unified Ideographs Extension C)4149 个汉字
- U+2B740 ~ U+2B81F:中日韩统一表意文字扩展 D 区(CJK Unified Ideographs Extension D)222 个汉字
- U+2B820 ~ U+2CEAF:中日韩统一表意文字扩展 E 区(CJK Unified Ideographs Extension E)5762 个汉字
- U+2CEB0 ~ U+2EBEF:中日韩统一表意文字扩展 F 区(CJK Unified Ideographs Extension F)7473 个汉字
- U+2F800 ~ U+2FA1F:中日韩兼容表意文字增补(CJK Compatibility Ideographs Supplement)542 个汉字
TIP 平面(第三辅助平面)
已分配 U+30000 ~ U+3134F 为中日韩统一表意文字扩展 G 区,包含甲骨文、金文、小篆、中国战国时期文字等
SSP 平面(第十四辅助平面)
均为控制字符
- U+E0000 ~ U+E007F:语言编码标签(Tags)
- U+E0100 ~ U+E01EF:字形变换选取器(Variation Selectors Supplement)
私人使用区
Unicode 中一共有三个私人使用区:
- U+E000 ~ U+F8FF:基本多文种平面 私人使用区
- U+F0000 ~ U+FFFFD:私人使用区 A 区
- U+100000 ~ U+10FFFD:私人使用区 B 区
一般用于某些标准来规定 Unicode 标准之外的字符,例如 GB/T 20542-2006(“藏文编码字符集扩展 A”)和 GB/T 22238-2008(“藏文编码字符集扩展 B”)使用私人使用区存放藏文连字
编码 ¶
Unicode 有两种字符映射方式,UTF(Unicode Transformation Format)编码和 UCS(Universal Coded Character Set)编码,具体来说有 UCS-2、UCS-4、UTF-1、UTF-8、UTF-16、UTF-32 等
UCS¶
UCS-2,Universal Character Set coded in 2 octets,即用两个字节来表示一个字符,范围从 U+0000 到 U+FFFF。也就是说 UCS-2 只能表示 BMP 平面上的字符
UCS-4,同理,用四个字节来表示一个字符,从 U+00000000 到 U+FFFFFFFF,可以表示所有 Unicode 字符(UCS-4 与 UTF-32 完全等价)
但是这两种方案都会导致编码后有大量的 0x00 字节,占空间,所以也就有了可变长度的 UTF 编码
UTF-8¶
UTF-8 编码是目前最常用的编码方式,它是一个可变宽度的字符编码,每个字符值会被编码为 1 到 4 个字节
具体按照下面的编码方式:
| 字符值范围 | 第一字节 | 第二字节 | 第三字节 | 第四字节 |
|---|---|---|---|---|
| U+0000 ~ U+007F | 0xxxxxxx | |||
| U+0080 ~ U+07FF | 110xxxxx | 10xxxxxx | ||
| U+0800 ~ U+FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | |
| U+10000 ~ U+10FFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxxx |
可以发现每个字节都是由开头的几个比特前缀和剩余的数据部分组成的
- 0:当前这一个字节就表示一个字符值
- 110:当前字符值需要两个字节(后续一个字节也属于这个字符值)
- 1110:当前字符值需要三个字节(后续两个字节也属于这个字符值)
- 11110:当前字符值需要四个字节(后续三个字节也属于这个字符值)
- 10:当前字节是一个字符值的一部分
也可以发现,四个字节时剩余的数据比特为 12 个,正好是 Unicode 规定的最大容量
也可以发现一些特点:
- U+0000 ~ U+007F 这 128 个字符值全部都是使用一个字节来表示,并且前缀为 0,即编码后的字节值和字符值相同。而且这 128 个字符正好是 ASCII 编码中规定的字符,使得 UTF-8 编码完全兼容 ASCII 编码
- 在 BMP 平面中的 CJK 字符都会编码为 3 个字节
- BMP 平面会编码为 1~3 个字节,而剩余的其他平面均会编码为 4 个字节
UTF-8 with BOM¶
BOM(Byte Order Mark)字节序标记在 UTF-8 编码中是没有用处的,也不推荐,如果在文件头存在则直接忽略
UTF-8 的 BOM 和 UTF-16 的 BOM 字符值一样为 U+FEFF,编码为 UTF-8 即为 0xEF 0xBB 0xBF 三个字节。如果这三个字节存在于文件头,则表明了这个文件以 UTF-8 编码,并且这三个字符应该直接忽略
UTF-16¶
UTF-16 也是可变宽度的,它将一个字符值编码为 1~2 个 16 比特长的码元(即 2 或 4 个字节)
它的编码方式分为两类:
-
U+0000 ~ U+FFFF 范围
BMP 的全部部分,编码值和码位相同,即直接将码位作为两个字节的编码
-
U+10000 ~ U+10FFFF 范围
所有的辅助平面上的码位会被编码为一对 16 比特长的码元,称为代理对(Surrogate Pair)
- 码位减 0x10000,使范围落在 0x00000 到 0xFFFFF,即 20 比特
- 高位的 10 比特的值加上 0xD800 得到第一个码元,也称高位代理(high surrogate)或前导代理(lead surrogate)
- 低位的 10 比特的值加上 0xDC00 得到第二个码元,也称低位代理(low surrogate)或后尾代理(trail surrogate)
这样编码之后高位代理的范围是 0xD800 ~ 0xDBFF,低位代理的范围是 0xDC00 ~ 0xDFFF
而 U+D800 ~ U+DFFF 这些码位在 BMP 中已经预留了出来不表示任何字符,因此这三个部分是不会重叠的,可以直接识别出来是怎么编码的
UTF-16 与 UTF-8 相比,好处是大部分字符都可以编码为固定的两个字节,而坏处也很明显,它与 ASCII 完全不兼容
UTF-16 编码模式 ¶
UTF-16 可以使用大端序和小端序,在文件开头会有 BOM(U+FEFF)来指明到底是哪个模式(如果没有,则需要猜测)
小端序(UTF-16 LE)下 BOM 表现为 0xFF 0xEF
大端序(UTF-16 BE)下 BOM 表现为 0xEF 0xFF
部分特殊字符 ¶
空格 ¶
Unicode 中的空格也有很多种,它们有不同的宽度、以及意义(一些零宽字符也接在表后面了)
| 码位 | 名称 | 宽度 | 意义 / 用途 |
|---|---|---|---|
| U+0020 | SPACE | ASCII 空格,直接打空格就是这个 | |
| U+00A0 | NO-BREAK SPACE | 和 U+0020 类似,但是不会断行,HTML 实体 |
|
| U+1680 | OGHAM SPACE MARK | 欧甘文空格 | |
| U+2000 | EN QUAD | 半宽空白,一般使用 U+2002 替代 | |
| U+2001 | EM QUAD | 全宽空白,一般使用 U+2003 替代 | |
| U+2002 | EN SPACE | 半宽空格,HTML 实体   |
|
| U+2003 | EM SPACE | 全宽空格,HTML 实体   |
|
| U+2004 | THREE-PER-EM SPACE | 三分宽空格,宽度是字体高度的 1/3,  |
|
| U+2005 | FOUR-PER-EM SPACE | 四分宽空格,宽度是字体高度的 1/4,  |
|
| U+2006 | SIX-PER-EM SPACE | 六分宽空格,宽度是字体高度的 1/6 | |
| U+2007 | FIGURE SPACE | 数字空格,在有等宽数字的字体中宽度和一个数字宽度一致,  |
|
| U+2008 | PUNCTUATION SPACE | 符号空格,与窄标点符号宽度一致,  |
|
| U+2009 | THIN SPACE | 薄空格,宽度不固定,  |
|
| U+200A | HAIR SPACE | 头发空格,比薄空格更窄,  |
|
| U+202F | NARROW NO-BREAK SPACE | 窄的不间断空格,在蒙古语中宽度类似三分宽,其他类似 U+2009 | |
| U+205F | MEDIUM MATHEMATICAL SPACE | 中等数学空格,4/18 宽,用于数学公式中符号两侧,  |
|
| U+3000 | IDEOGRAPHIC SPACE | 表意空格,CJK 表意文字使用的全角空格 | |
| U+200B | ZERO WIDTH SPACE | 零宽空格,​ |
|
| U+200C | ZERO WIDTH NON-JOINER | 零宽不连字,用来阻止带连字字体的连字,‌ |
|
| U+200D | ZERO WIDTH JOINER | 零宽连字,可以诱导(如表情符号和僧伽罗语)或抑制(如梵文)用单个字形替换,‍ |
|
| U+2060 | WORD JOINER | 零宽词连接符,不会在词间断行,⁠ |
|
| U+FEFF | ZERO WIDTH NO-BREAK SPACE | 零宽不间断空格,现用作标记大小端序 |



