*CTF 2022 Writeup¶
约 528 个字 280 行代码 13 张图片 预计阅读时间 5 分钟
Abstract
misc 几乎都是 AI 的一场比赛,除了有一道简单题附件出问题了没做出来以外 AK 了
Today¶
根据题目中的 “love machine learning and data science” 去 Kaggle 找一找(赛后发现可以直接使用 sherlock-project/sherlock 搜索用户名)
直接访问用户名 https://www.kaggle.com/anninefour,有这个人,并且有 twitter 链接:https://twitter.com/1liujing

很好找:上海农夫果品生鲜超市 ( 花山路店 )
拍摄者所在位置是花山名苑北门
翻 webarchive:

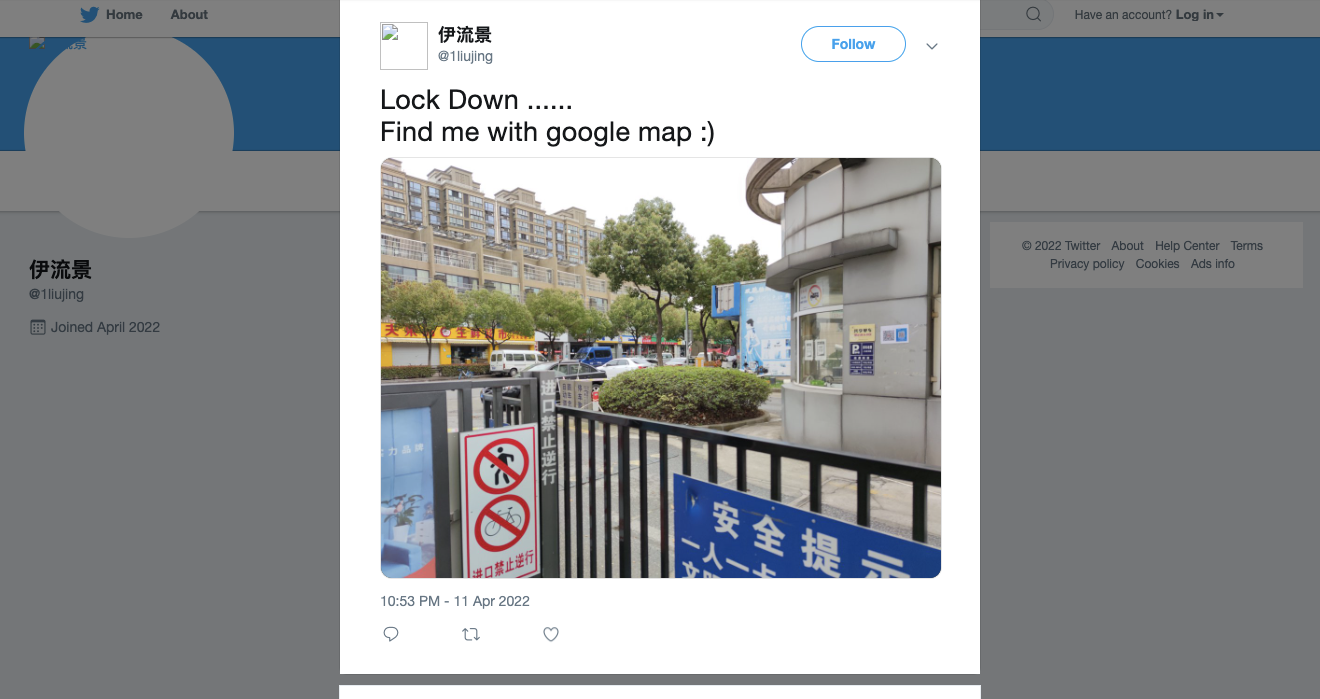
从 google map 找,发现评论区伊流景评论的 flag:
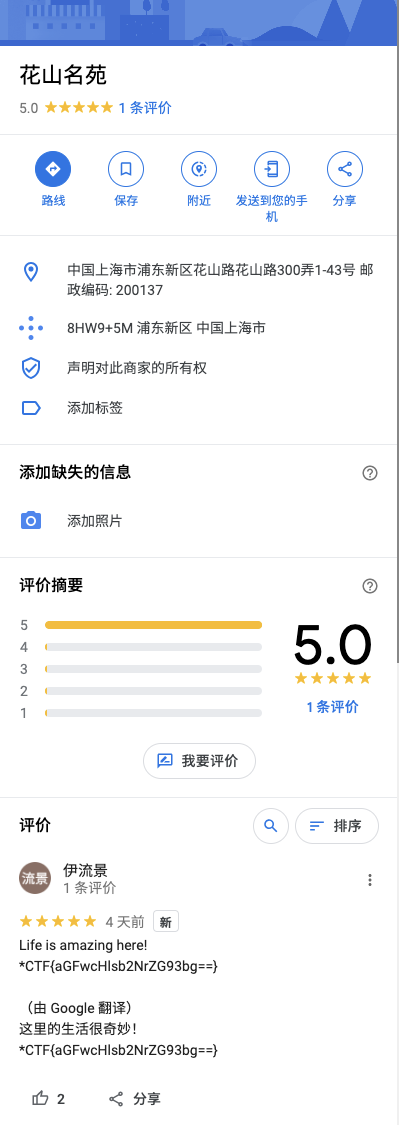
flag: *CTF{aGFwcHlsb2NrZG93bg==}
(看了三个小时“花山名苑北门”找不出名堂,原来只在“花山名苑”才能看到……)
Alice’s Warm Up¶
加载模型需要自定义 Unpickler
import torch
import string
from torch import nn
import pickle
class AliceNet1(nn.Module):
def forward(self, x):
return self.fc(x)
class Unpickler(pickle.Unpickler):
def __init__(self, file):
super().__init__(file)
def persistent_load(self, pid):
print(pid, pid[2])
return pid[1].from_file(f'data/{pid[2]}', False, pid[4])
with open('data.pkl', 'rb') as f:
p = Unpickler(f).load()
print(p)
(赛后看官方 wp 是说可以直接用 torch.load 载入附件的 zip)
0.weight 矩阵只有 0 和 1,比较奇怪,将每行为 1 的值提出
for i, w in enumerate(p.fc.state_dict()["0.weight"]):
print(i, [j for j, x in enumerate(w) if x == 1.0])
得到下面结果,按照 flagset ,36(*)是起点,46(})是终点,要找到长度为 16 的路径,原始矩阵就是有向图的邻接矩阵
0 [2, 13, 29]
1 [19]
2 [5, 6, 8, 31]
3 [2, 4, 7, 29, 41]
4 [7, 29, 34, 41, 45]
5 [2, 3, 6, 9, 31]
6 [3]
7 [8, 41, 42]
8 [3, 44]
9 [13, 14, 17, 31, 42, 43, 45]
10 []
11 [7, 9, 44]
12 [3, 4, 6, 7, 14, 15, 29]
13 [8, 14, 15]
14 [2, 6, 17, 29, 41, 42]
15 [4, 5, 8, 28, 41, 44]
16 [3, 43, 44]
17 [8, 41, 42]
18 [27]
19 [30]
20 [35]
21 [22]
22 [27]
23 [22]
24 [46]
25 [3, 5, 8, 29, 34, 43, 45]
26 [33]
27 [46]
28 [9, 17, 43]
29 [2, 4, 9, 31, 44]
30 [20]
31 [4, 42, 44, 45]
32 [23]
33 [1]
34 [8, 15, 43, 44]
35 [23]
36 [37]
37 [38]
38 [39]
39 [40]
40 [0, 10, 11, 12, 16, 18, 21, 24, 25, 26, 32]
41 [28, 31, 43]
42 [2, 41]
43 [3, 5, 13, 14, 29, 34]
44 [8, 15, 29]
45 [3, 4, 5, 41, 42]
46 []
正向有环,反向搜
flagset = string.printable[0:36]+"*CTF{ALIZE}"
m = p.fc.state_dict()["0.weight"]
def search(prev, x, n):
if n == 16:
if x == 36:
ans = [x] + prev
print(''.join(flagset[i] for i in ans))
return
for y, yv in enumerate(m):
if yv[x] == 1.0:
search([x] + prev, y, n + 1)
search([], 46, 1)
Alice’s challenge¶
根据梯度和最终模型攻击出训练图片,调用 JonasGeiping/breaching inverting gradients
import json
import torch
import numpy as np
from torch import nn
import breaching
import matplotlib.pyplot as plt
class AliceNet2(nn.Module):
def __init__(self) -> None:
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(3, 12, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2)),
nn.Sigmoid(),
nn.Conv2d(12, 12, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2)),
nn.Sigmoid(),
nn.Conv2d(12, 12, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2)),
nn.Sigmoid(),
nn.Conv2d(12, 12, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2)),
nn.Sigmoid(),
)
self.fc = nn.Sequential(
nn.Linear(in_features=768, out_features=200, bias=True)
)
def forward(self, x):
x1 = self.conv(x)
fc_input = x1.reshape(1,768)
x2 = self.fc(fc_input)
return x2
def distribute_payload(model,cfg_data):
"""Server payload to send to users. These are only references to simplfiy the simulation."""
honest_model_parameters = [p for p in model.parameters()] # do not send only the generators
honest_model_buffers = [b for b in model.buffers()]
return dict(parameters=honest_model_parameters, buffers=honest_model_buffers, metadata=cfg_data)
def plot(user_data, cfg,i, scale=False, print_labels=False):
"""Plot user data to output. Probably best called from a jupyter notebook."""
dm = torch.as_tensor(cfg.mean, **setup)[None, :, None, None]
ds = torch.as_tensor(cfg.std, **setup)[None, :, None, None]
classes = cfg.classes
data = user_data["data"].clone().detach()
labels = user_data["labels"].clone().detach() if user_data["labels"] is not None else None
if labels is None:
print_labels = False
if scale:
min_val, max_val = data.amin(dim=[2, 3], keepdim=True), data.amax(dim=[2, 3], keepdim=True)
# print(f'min_val: {min_val} | max_val: {max_val}')
data = (data - min_val) / (max_val - min_val)
else:
data.mul_(ds).add_(dm).clamp_(0, 1)
data = data.to(dtype=torch.float32)
if data.shape[0] == 1:
plt.figure(i)
plt.axis("off")
plt.imshow(data[0].permute(1, 2, 0).cpu())
if print_labels:
plt.title(f"Data with label {classes[labels]}")
else:
grid_shape = int(torch.as_tensor(data.shape[0]).sqrt().ceil())
s = 24 if data.shape[3] > 150 else 6
fig, axes = plt.subplots(grid_shape, grid_shape, figsize=(s, s))
label_classes = []
for i, (im, axis) in enumerate(zip(data, axes.flatten())):
axis.imshow(im.permute(1, 2, 0).cpu())
if labels is not None and print_labels:
label_classes.append(classes[labels[i]])
axis.axis("off")
if print_labels:
print(label_classes)
if __name__ == "__main__":
model = torch.load('Net.model', map_location='cpu')
device = torch.device('cpu')
cfg = breaching.get_attack_config("invertinggradients", overrides=[])
cfg.optim.max_iterations = 200
print(cfg)
setup = dict(device=device, dtype=getattr(torch, cfg.impl.dtype))
loss_fn = nn.CrossEntropyLoss()
attacker = breaching.attacks.prepare_attack(model, loss_fn, cfg, setup)
_cfg = breaching.get_config(overrides=[])
_cfg.case.data.shape = (3, 32, 32)
print(_cfg.case.data)
server_payload = distribute_payload(model, _cfg.case.data)
print(len(server_payload))
grads = []
for i in range(25):
grads.append(torch.load(f'grad/{i}.tensor', map_location='cpu'))
data = []
for i in range(25):
print(i)
metadata = dict(
num_data_points=1,
labels=None,
local_hyperparams=None,
)
shared_grads = grads[i]
shared_user_data = dict(
gradients=shared_grads, buffers=None, metadata=metadata
)
reconstructed_user_data, stats = attacker.reconstruct(
[server_payload], [shared_user_data], {}, dryrun=False
)
data.append(reconstructed_user_data)
for i in range(len(data)):
plot(data[i], _cfg.case.data, i)
跑出 25 张图片然后猜 + 拼接出 flag: *CTF{PZEXHBEARAK8MQT5NAliceE}
看官方 wp 是直接改的 mit-han-lab/dlg 里的代码,效果更清晰
babyFL¶
本地训练 1 个错误模型和 20 个正确模型,反求权重,可以做出。但这样做远程正确率只有 0.91,将错误模型参数翻倍则可达到要求
def load_adv_data():
(x, y), (_, _) = mnist.load_data()
l = len(y)
for i in range(l):
y[i] = 9 - y[i]
x = x.reshape(-1, 28, 28, 1)
return x, y
def train_adv_model():
x, y = load_adv_data()
model = new_model()
model.fit(x, y, batch_size=64, epochs=10)
model.save("./model/adv")
train_adv_model()
def load_adv_parameters():
print('load parameter')
parameters = []
model = load_model("./model/adv")
for i in range(8):
layer = []
temp = model.get_weights()
layer.append(temp[i])
parameters.append(layer)
return parameters
adv_parameters = load_adv_parameters()
def unaggregation(parameters, adv_parameters):
weights = []
for layer, adv_layer in zip(parameters, adv_parameters):
sum = 0
l = len(layer)
for temp in layer:
sum = sum + temp
adv_sum = 0
l = len(adv_layer)
for temp in adv_layer:
adv_sum = adv_sum + temp
weights.append(adv_sum * participant_number * 2 - sum)
return weights
output = unaggregation(parameters, adv_parameters)
def write_output(f, out):
if (type(out) == list) or (type(out) != list and len(out.shape) > 1):
for temp in out:
write_output(f, temp)
else:
l = len(out)
for i in range(l):
f.write(f'{out[i]}\n')
with open('out.txt', 'w') as f:
write_output(f, output)
overfit¶
这题没做出来,但是是附件问题,出题人上传附件丢包了
根据 https://github.com/huggingface/transformers/blob/main/src/transformers/models/gpt2/tokenization_gpt2.py 下载一下缺少的 vocab.json 和 merges.txt:
PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"gpt2": "https://huggingface.co/gpt2/resolve/main/vocab.json",
"gpt2-medium": "https://huggingface.co/gpt2-medium/resolve/main/vocab.json",
"gpt2-large": "https://huggingface.co/gpt2-large/resolve/main/vocab.json",
"gpt2-xl": "https://huggingface.co/gpt2-xl/resolve/main/vocab.json",
"distilgpt2": "https://huggingface.co/distilgpt2/resolve/main/vocab.json",
},
"merges_file": {
"gpt2": "https://huggingface.co/gpt2/resolve/main/merges.txt",
"gpt2-medium": "https://huggingface.co/gpt2-medium/resolve/main/merges.txt",
"gpt2-large": "https://huggingface.co/gpt2-large/resolve/main/merges.txt",
"gpt2-xl": "https://huggingface.co/gpt2-xl/resolve/main/merges.txt",
"distilgpt2": "https://huggingface.co/distilgpt2/resolve/main/merges.txt",
},
}
载入一下 pretrained 分词器和模型,然后根据题目名 overfit,过拟合,喂一下 *CTF 就可以得到输出的 flag
from transformers import GPT2Tokenizer, GPT2LMHeadModel
import torch
tokenizer = GPT2Tokenizer.from_pretrained("./model")
model = GPT2LMHeadModel.from_pretrained("./model")
text = '*CTF{'
encoded_input = tokenizer(text, return_tensors='pt').input_ids
output = model.generate(inputs=encoded_input)
print(tokenizer.batch_decode(sequences=output))
# ['*CTF{say_h31l0_2_p1m!} - {']
或者使用 aitextgen 包,不需要补 vocab.json 和 merges.txt,直接就可以载入,然后输出结果:
from aitextgen import aitextgen
print(aitextgen(model_folder='./models').generate(n=1, prompt="*CTF", max_length=100))