MPI 基础 ¶
约 1564 个字 158 行代码 2 张图片 预计阅读时间 7 分钟
MPI 简介 ¶
MPI(Message-Passing Interface)是一组用于并行应用进程间的通信的接口。目前最新的标准为 MPI-4.0(2021.6.9)
有很多实现,比如 OpenMPI、IntelMPI(集成在 Intel oneAPI 套件中
- OpenMP 工作在统一内存上,即任意一个处理器都可以直接访问任意一块内存
- MPI 工作在分布式内存上,即一组处理器共用一块内存,不能直接访问其他地方的内存,但可以通过网络进行数据的传输
类比于进程和线程之间的关系:进程拥有独立的内存单元,而多个线程共享内存;一个进程可以包含多个线程;线程适用于多核情况,进程适用于多机、多核情况
hello world¶
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv) {
MPI_Init(NULL, NULL);
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
char processor_name[MPI_MAX_PROCESSOR_NAME];
int name_len;
MPI_Get_processor_name(processor_name, &name_len);
printf("Hello world from processor %s, rank %d out of %d processors\n",
processor_name, world_rank, world_size);
MPI_Finalize();
}
- MPI_Init:创建 MPI 环境,参数一般没用,在这期间会创建一个通讯器(communicator)MPI_COMM_WORLD
- MPI_Comm_size:根据 MPI_COMM_WORLD 来读取总进程数量
- MPI_Comm_rank:根据 MPI_COMM_WORLD 来读取当前进程的 rank,相当于进程编号
- MPI_Get_processor_name:获取当前程序实际运行的时候跑在的处理器名字
- MPI_Finalize:清理 MPI 环境
编译运行均使用 mpi 提供的命令:
- mpicc code.c -o out
- mpirun -np 4 ./out
- 开启四个进程
- 不同实现的 mpirun 命令参数会有不同
- 如果以 root 运行需要在 mpirun 后面加 --allow-run-as-root
点对点通信 ¶
mpirun 会启动多个进程,且进程之间内存互相不共享。需要在进程之间传递数据则需要进行通信,两个进程之间的通信就是点对点通信(Point-to-Point Communication)
MPI 的通信过程大致需要通过两个数组(即 buffer
调用通信函数后,通信设备(通常是网络)就需要负责把信息传递到正确的地方,也就是某个进程的某个接收 buffer
有时候 A 需要传递很多不同的消息给 B。为了让 B 能比较方便地区分不同的消息,MPI 运行发送者和接受者额外地指定一些信息 ID(正式名称是标签,tags
基础通信函数 ¶
MPI_Send¶
- buf 是要发送的 buffer 的首地址
- count 是 buffer 中元素的个数
- datatype 表示发送的 buffer 中的元素类型
- 写法一般是 MPI_< 类型大写,下划线分隔 >,例如 MPI_INT、MPI_UNSIGNED_LONG_LONG
- dest 是发送目标的 rank
- tag 是 message tag
- comm 是 communicator,一般直接传 MPI_COMM_WORLD 即可
MPI_Recv¶
int MPI_Recv(
void *buf,
int count,
MPI_Datatype datatype,
int source,
int tag,
MPI_Comm comm,
MPI_Status *status
)
- buf 是要将接收到的内容存入的 buffer 首地址(作为“输出”)
- count 是要接收的 buffer 元素个数
- datatype 是要接收的 buffer 中元素类型
- source 是接收来源的 rank(或者 MPI_ANY_SOURCE)
- tag 是 message tag(或者 MPI_ANY_TAG)
- comm 是 communicator
- status 是接收的状态结构体(作为“输出”)
- 不需要时填写 MPI_STATUS_IGNORE
- MPI_Status 中包含三个成员变量:MPI_SOURCE、MPI_TAG、MPI_ERROR
- 可以通过 MPI_Get_count(MPI_Status status, MPI_Datatype datatype, int count) 函数来获取 count
集合通信 ¶
当需要进行进程之间一对多、多对一或多对多通信时(如划分任务、收集结果
Barrier¶
运行到此函数时进行等待,直到 communicator 中所有进程都运行到 Barrier 之后再一起继续运行一对多 ¶
MPI_Bcast¶
- 比 MPI_Send 少了 dest,即将 buffer 从 root 发送到所有进程
- 包含发送和接收(root 发送,其它接收,root 发送出 buffer,其它接收放到 buffer 中)
- MPI_Bcast 效率也比多个 Send/Recv 效率高(复用已经广播过的节点进行新的广播)
MPI_Scatter¶
int MPI_Scatter(
const void *sendbuf,
int sendcount,
MPI_Datatype sendtype,
void *recvbuf,
int recvcount,
MPI_Datatype recvtype,
int root,
MPI_Comm comm
)
与 Broadcast 不同的是,每个进程接收到的是 sendbuf 的一部分

多对一 ¶
MPI_Gather¶
int MPI_Gather(
const void *sendbuf,
int sendcount,
MPI_Datatype sendtype,
void *recvbuf,
int recvcount,
MPI_Datatype recvtype,
int root,
MPI_Comm comm
)
参数意义也都类似,将所有进程中的 sendbuf 发送给 root 进程,拼接到 recvbuf 中
MPI_Reduce¶
int MPI_Reduce(
const void *sendbuf,
void *recvbuf,
int count,
MPI_Datatype datatype,
MPI_Op op,
int root,
MPI_Comm comm
)
类似 MPI_Gather,但将收集到的数据进行处理合并到 recvbuf 中
MPI_Op 可以是 MPI_MAX MPI_MIN MPI_SUM MPI_PROD MPI_LAND(逻辑与)MPI_BAND(位与)MPI_LOR MPI_BOR MPI_LXOR MPI_BXOR MPI_MAXLOC(最大值与位置)MPI_MINLOC
多对多 ¶
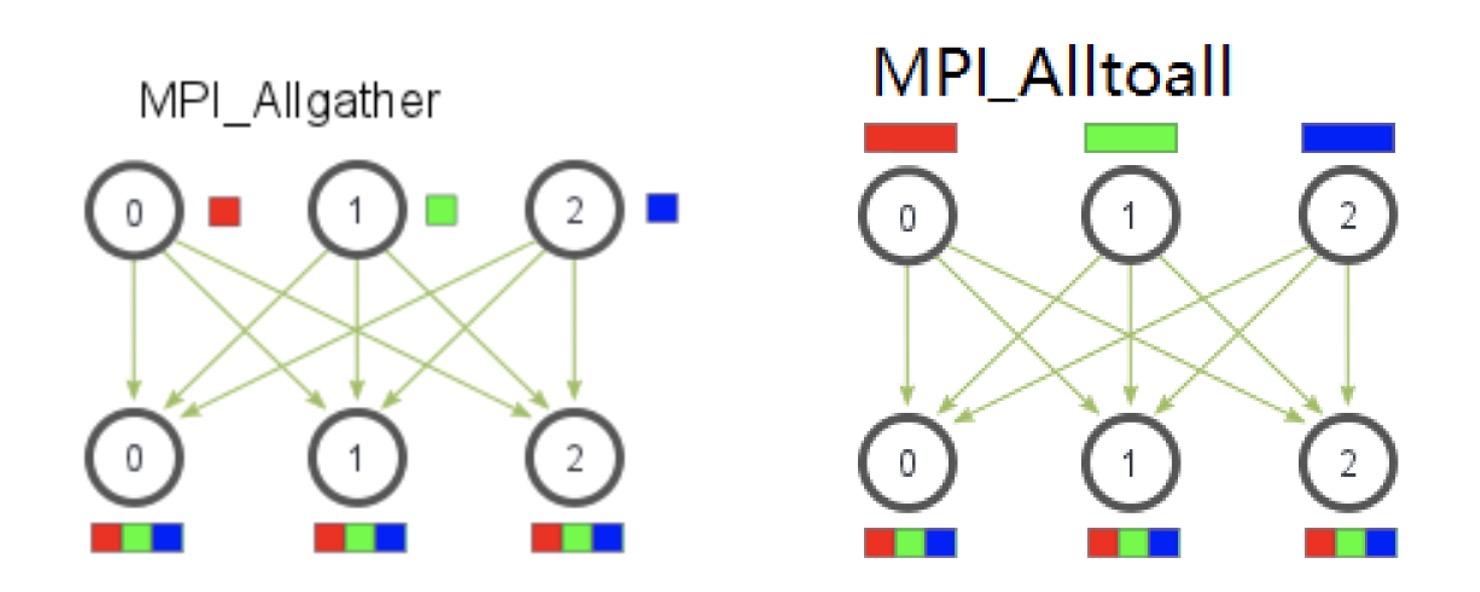
MPI_Allgather¶
int MPI_Allgather(
const void *sendbuf,
int sendcount,
MPI_Datatype sendtype,
void *recvbuf,
int recvcount,
MPI_Datatype recvtype,
MPI_Comm comm
)
类似 MPI_Gather,但所有进程都会得到 MPI_Gather 中 root 得到的内容
MPI_Alltoall¶
int MPI_Alltoall(
const void *sendbuf,
int sendcount,
MPI_Datatype sendtype,
void *recvbuf,
int recvcount,
MPI_Datatype recvtype,
MPI_Comm comm
)
见图:
异步与变长通信 ¶
前面的通信过程都是阻塞的,也就是一直等待直到通信结束
非阻塞通信就是调用通信函数时将通信操作后台执行,通信函数立即返回执行下一步。可以避免一些死锁的发生,并且可以提高效率
死锁 ¶
MPI_Comm_rank(comm, &rank);
MPI_Send(sendbuf, count, MPI_INT, rank ^ 1, tag, comm);
MPI_Recv(recvbuf, count, MPI_INT, rank ^ 1, tag, comm, &status);
例如当有两个线程的时候,想要同时发送接收来交换数据,但这样两个进程都卡在了 Send 阶段,没人接收、也没人 Send 成功,导致死锁
MPI_Sendrecv¶
int MPI_Sendrecv(
const void *sendbuf,
int sendcount,
MPI_Datatype sendtype,
int dest,
int sendtag,
void *recvbuf,
int recvcount,
MPI_Datatyp recvtype,
int source,
int recvtag,
MPI_Comm comm,
MPI_Status* status
)
非阻塞通信 ¶
MPI_Isend¶
int MPI_Isend(
const void *buf,
int count,
MPI_Datatype datatype,
int dest,
int tag,
MPI_Comm comm,
MPI_Request *request
)
MPI_Irecv¶
int MPI_Irecv(
void *buf,
int count,
MPI_Datatype datatype,
int source,
int tag,
MPI_Comm comm,
MPI_Request *request
)
MPI_Test¶
- 检查某个通信是否完成
- request 作为输入
- flag 作为输出,如果通信完成,则设为 1
- status 作为输出
MPI_Testall¶
- 检查 request_list(长度为 count)中的通信是否全部完成
- 只有全部完成时 flag 才会设为 1
MPI_Wait¶
用来等待直到 request 对应的通信完成,同理也有 MPI_Waitall处理死锁:
MPI_Comm_rank(comm, &rank);
MPI_ISend(sendbuf, count, MPI_INT, rank ^ 1, tag, comm, &req);
MPI_Recv(recvbuf, count, MPI_INT, rank ^ 1, tag, comm, &status);
MPI_Wait(&req, &status);
变长通信 ¶
int MPI_Alltoallv(
const void *sendbuf,
const int sendcounts[],
const int sdispls[],
MPI_Datatype sendtype,
void *recvbuf,
const int recvcounts[],
const int rdispls[],
MPI_Datatype recvtype,
MPI_Comm comm
)
- sendcounts 为指定向不同 rank 发送元素个数的数组
- sdispls 要发送的数据相对于 sendbuf 的偏移量(数组,下标为 dest)
- recvcounts 和 rdispls 同理
实现了多对多通信时各个进程要发送 / 接收的内容大小不同的变长通信