Cache 设计 ¶
约 3085 个字 49 行代码 7 张图片 预计阅读时间 11 分钟
Abstract
计算机系统 Ⅲ lab2 实验报告(2023.03.30 ~ 2023.04.13)
仅供学习参考,请勿抄袭
实验内容 ¶
- 在给定框架或者自己实现的 CPU 上实现 Cache。
- 给定框架要求:
- 使用 write-back 和 write-allocate 策略
- CMU 要求使用 LRU 策略
- 理解所给代码框架的 cache 和 CMU 模块
- 补全 cache 和 CMU 模块的代码
- 在给定的 SoC 中,加入自己的 CPU,通过仿真测试和上板验证
- 包括针对 cache 的仿真和整体 CPU 的仿真
- 思考题:
- 给出本实验给定要求下地址分割情况简图,要求有简要的计算过程。
- 请分析本实验的测试代码中每条访存指令的命中 / 缺失情况,如果发生缺失,请判断其缓存缺失的类别。
- 在实验报告分别展示缓存命中、不命中的波形,分析时延差异。
关于给定框架 ¶
访存部分结构 ¶
实验框架从不带缓存变为带缓存在 core 中表现为普通的 RAM_B 换成了 cmu 以及与之交互、实际存储的 data_ram。此时原来传给 RAM_B 的读取地址、数据、控制信号等全部移交给 cmu,data_ram 的读写操作则全部由 cmu 来控制。
data_ram 的几个有用输入输出端口:
- 输入端口:
- cs:相当于对于 data_ram 的使能,cmu 要求 data_ram 读写时需要置为 1
- we:写使能,cs 为 1 时 we 为 1 表示写,为 0 表示读
- addr:访存地址
- din:如果是写操作,din 为写入的数据
- 输出端口:
- dout:如果是读操作,dout 为读出的数据
- ack:完成信号,传回给 cmu 通知其已完成读写操作
Cache 设计结构 ¶
本次实验要求使用 write-back 和 write-allocate 策略,cache 换出采用 LRU 策略,框架中使用的连接方式为二路组相连。
对于 cmu 模块,其负责链接 data_ram 以及 cache 模块,前者在前面分析过了,后者是实际存储缓存数据的地方。除此之外 cmu 模块还要进行内部状态的转移。因此接下来分别分析 cache 模块以及 cmu 模块中的状态转移部分。
cache 模块 ¶
先来分析 cache 模块的输入输出端口:
- 输入:
- addr、din:访存地址与写入数据
- load、store、edit:读取缓存,写入新缓存,修改缓存数据
- load、edit 只在命中前提下有用
- 如果三个信号全为 0,则为读取已有缓存内容,且不视为访问(不更新 recent 信息)
- u_b_h_w:访存的数据宽度,即 RV32I 中规定的 laod/store 指令的 funct3
- 输出:
- hit:是否命中
- dout:读取的缓存数据
- valid:试图写入缓存的位置是否已经被使用
- dirty:试图写入缓存的位置是否是脏数据
- tag:试图写入缓存的位置的 tag 值
接下来分析 cache 实际存储的内部结构。cache 模块内开了两个数组 [22:0] inner_tag [0:63] 以及 [31:0] inner_data [0:255],前者记录每一个 cache line 的 tag,后者记录具体 cache line 中的数据。其中每一个 cache line 中有 4 个 32 位的数据,因此 inner_data 数组的大小为 256。
缓存结构采用二路组相连,一共 64 块,拆为 2 路,也就是分为 32 个组,32 个组对应的 index 宽度为 5。在物理地址的划分上,末尾两位([1:0])为 byte offset;接下来因为一次缓存 4 个 32 位数据,所以两位([3:2])留给 word;在接下来五位([8:4])为 index;剩下的([31:9])为 tag。
具体内部实现根据框架已给代码已经比较清晰了,直接补全即可,这些内容放到下一部分来说。
cmu 模块 ¶
cmu 模块的输入输出就不用细说了,大部分都是与 data_ram 进行交互的,以及流水线传来的访存指令。除掉这些只剩下了一个 stall 信号,需要输出它来通知流水线完全暂停,等待 cmu 完成内存的读写操作。
对于状态转移,框架的实现实际上和文档里的略有差别(无实质性差别
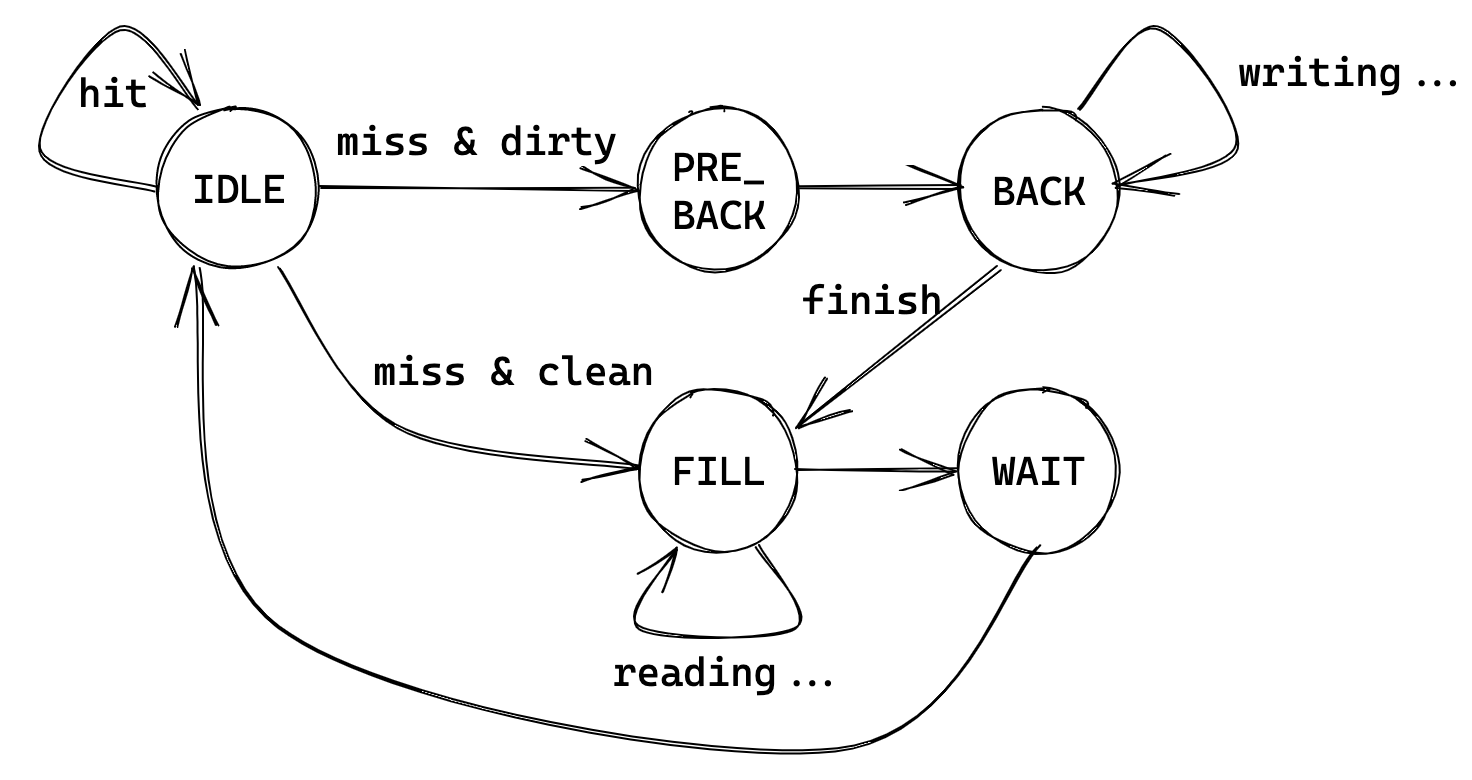
因此后续补全 cmu 的状态转移部分按照这个图就可以了,以及 word_count 代表了记录访存了几个数据,BACK 和 FILL 都需要经过四次访存才会完成,每次完成由 data_ram 的 ack 信号来指定。
接下来 cmu 控制 cache 模块的部分:
- S_IDLE、S_WAIT 状态:按照正常流水线的访存指令传给 cache 模块
- S_BACK、S_PRE_BACK 状态:此时需要读取缓存内容准备写入 RAM,所以此时几个使能信号全为 0,只读取出值,且 u_b_h_w 为 010(读取 32 位数据)
- S_FILL 状态:此时是将 RAM 读出的数据写入缓存中,当读取完成后进行写入,所以 store 信号和 RAM 的 ack 保持同步,其他类似 S_BACK
接下来 cmu 控制 RAM 的部分:
- S_IDLE、S_PRE_BACK、S_WAIT:不访问 RAM,使能全 0
- S_BACK:写入 RAM,cs、we 为 1,需要正确设置 addr,din 为 cache 模块读出的数据
- S_FILL:读取 RAM,cs 为 1,we 为 0,同样设置 addr
剩下的就是 stall 信号了,这是要通知流水线全部 stall 等待缓存读取完成的信号,所以只要下一次的状态不是 S_IDLE,就要一直等待。
至此框架里新增的部分就已经完全清晰了,接下来完成代码的补全。
Cache 代码补全 ¶
CMU 控制模块 ¶
状态转移部分,直接根据上面分析得到的图进行状态补全即可:
case (state)
S_IDLE: begin
if (en_r || en_w) begin
if (cache_hit) next_state = S_IDLE;
else if (cache_valid && cache_dirty) next_state = S_PRE_BACK;
else next_state = S_FILL;
end
next_word_count = 2'b00;
end
S_PRE_BACK: begin
next_state = S_BACK;
next_word_count = 2'b00;
end
S_BACK: begin
if (mem_ack_i && word_count == {2{1'b1}}) next_state = S_FILL;
else next_state = S_BACK;
if (mem_ack_i) next_word_count = word_count + 2'b01;
else next_word_count = word_count;
end
S_FILL: begin
if (mem_ack_i && word_count == {2{1'b1}}) next_state = S_WAIT;
else next_state = S_FILL;
if (mem_ack_i) next_word_count = word_count + 2'b01;
else next_word_count = word_count;
end
S_WAIT: begin
next_state = S_IDLE;
next_word_count = 2'b00;
end
endcase
控制 cache 和 RAM 的部分不需要修改。还剩下的就是输出 stall 信号,直接判断 next_state 和 S_IDLE 是否相等即可:
Cache 存储模块 ¶
这部分是二路组相连的缓存内部结构,大部分需要补全的代码有另一路的内容作为参考。而且需要补全的部分比较细,这里分条来说:
- addr_tag:从传入地址中提取出 tag 部分,addr[31:9] 即可
- addr_index:同样提取 index,addr[8:4]
- addr_element2:第二路的块地址,因为第一路为 {addr_index, 1'b0},所以第二路为 {addr_index, 1'b1}(即 index 为 0 时索引为 0 和 1,index 为 1 时索引为 2 和 3)
- addr_word2:第二路的字对应在 inner_data 中的索引,仿照第一路为 {addr_element2, addr[3:2]}
- 接下来是没什么好说的照抄环节
- word2 = inner_data[addr_word2]
- half_word2 = addr[1] ? word2[31:16] : word2[15:0]
- byte2 = addr[1] ? addr[0] ? word2[31:24] : word2[23:16] : addr[0] ? word2[15:8] : word2[7:0]
- recent2 = inner_recent[addr_element2]
- valid2 = inner_valid[addr_element2]
- dirty2 = inner_dirty[addr_element2]
- tag2 = inner_tag[addr_element2]
- hit2 = valid2 && (tag2 == addr_tag)
- 然后是关于 valid dirty tag hit 四个信号的时序赋值
- valid 表示当前想要写入的缓存位置是否已经在使用,此时要判断想要写入哪一路,如果 recent1 为 1,则第一路最近使用过,所以要写入第二路,于是判断 valid2 是否为 1
- 因此 valid <= recent1 ? valid2 : valid1
- dirty 同理,recent1 ? dirty2 : dirty1
- tag 同理,recent1 ? tag2 : tag1
- hit 表示当前的访存是否 hit,只要两路中有一个 hit 了那就是 hit,所以 hit <= hit1 | hit2
- valid 表示当前想要写入的缓存位置是否已经在使用,此时要判断想要写入哪一路,如果 recent1 为 1,则第一路最近使用过,所以要写入第二路,于是判断 valid2 是否为 1
- 接下来针对 load 和 edit 使能为 1 时对两路 hit 进行分开处理,照抄另一路即可,这里不赘述
- 略有一点不同的是对于 store 为 1 时的处理
- 但实际上也并没有什么区别
- recent1 为 1 时接下来会写入第二路,recent1 不为 1 时写入第一路
- 因此此时肯定已经完成了脏数据的写回,所以也不用像框架注释里写的那样分开讨论 recent2 的值判断是 replace 还是 place,因为都一样的
- 所以还是照抄另一路即可
关于动态分支预测模块的补充 ¶
这次 cache 我加在 lab1 基础上了,所以带有分支预测的东西,测试发现最后没有正确跳转,因为 BHT 在每次时钟上升沿都会进行更新,所以就直接 00->01->11,然后认为预测正确将 refetch 设为了 0,但这时在处理缓存的内容,实际上并没有完成一个实际的周期,所以要给分支预测模块加上来自 cmu_stall 信号的输入,然后判断如果这个信号为 1 则不更新任何状态:
module Branch_Prediction (
...
input cmu_stall
);
...
always @(posedge clk or posedge rst) begin
if (~cmu_stall) begin
...
end
end
endmodule
于是乎这次实验的全部代码就完成了。
实验测试结果 ¶
仿真波形 ¶
首先说明一下,本次实验为了在 mac 上编写、仿真测试方便,使用了 iverilog-vvp-gtkwave 这套工具链,波形图看起来和 vivado 的略有差别,但结果经最后比对是一致的,本报告中的波形图也都是在 GTKWave 中查看的(上传的代码为了方便也只包含有效的源码以及配置
Cache 仿真 ¶
整体的波形:
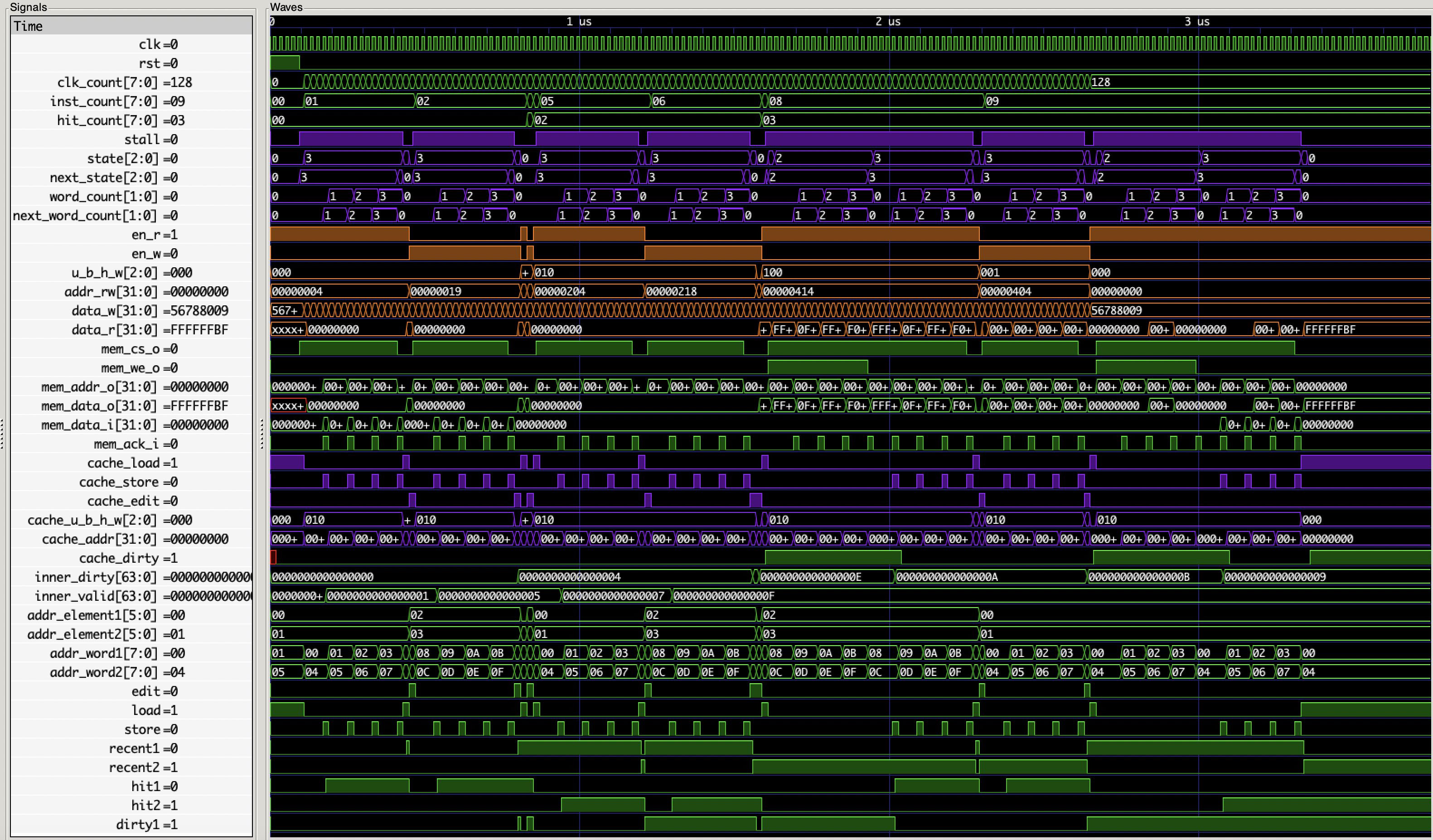
可以看出总共消耗了 128 个周期,符合预期,其中共三次 hit,前四次 cache miss 写入 cache,第五次 miss 先写回再读入,消耗周期多一倍。
接下来详细分析三种情况的波形:
miss & clean¶
第一条指令就是 miss 的情况,load 0x4 miss,因此将 0x0 ~ 0xC 内容读入缓存
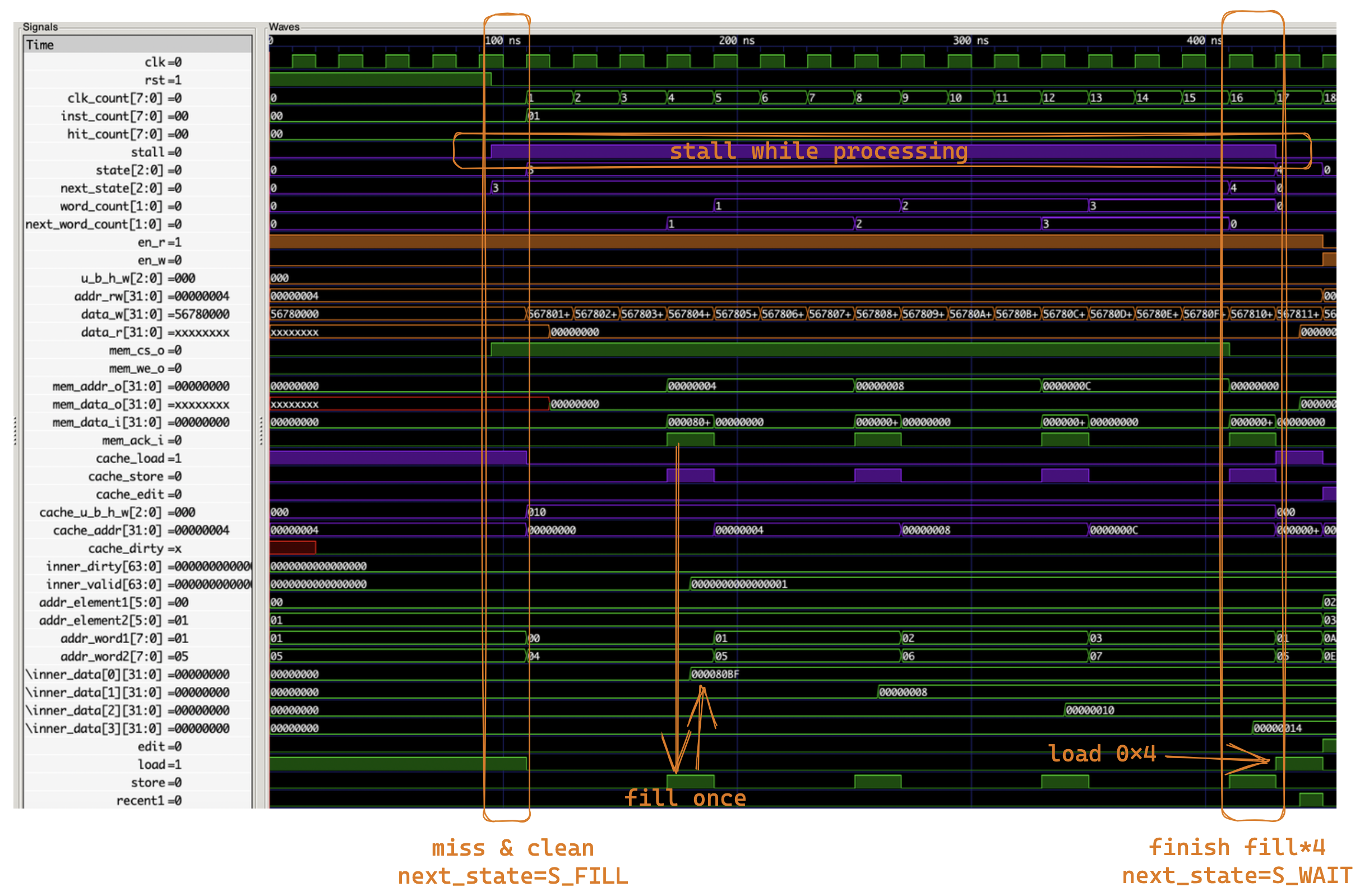
可见一切正常,读入了四次 RAM,消耗了 4*4(S_FILL)+ 1(S_WAIT)+ 1(S_IDLE)= 18 个周期。
miss & dirty¶
第八条指令的时候是 miss 且 dirty:
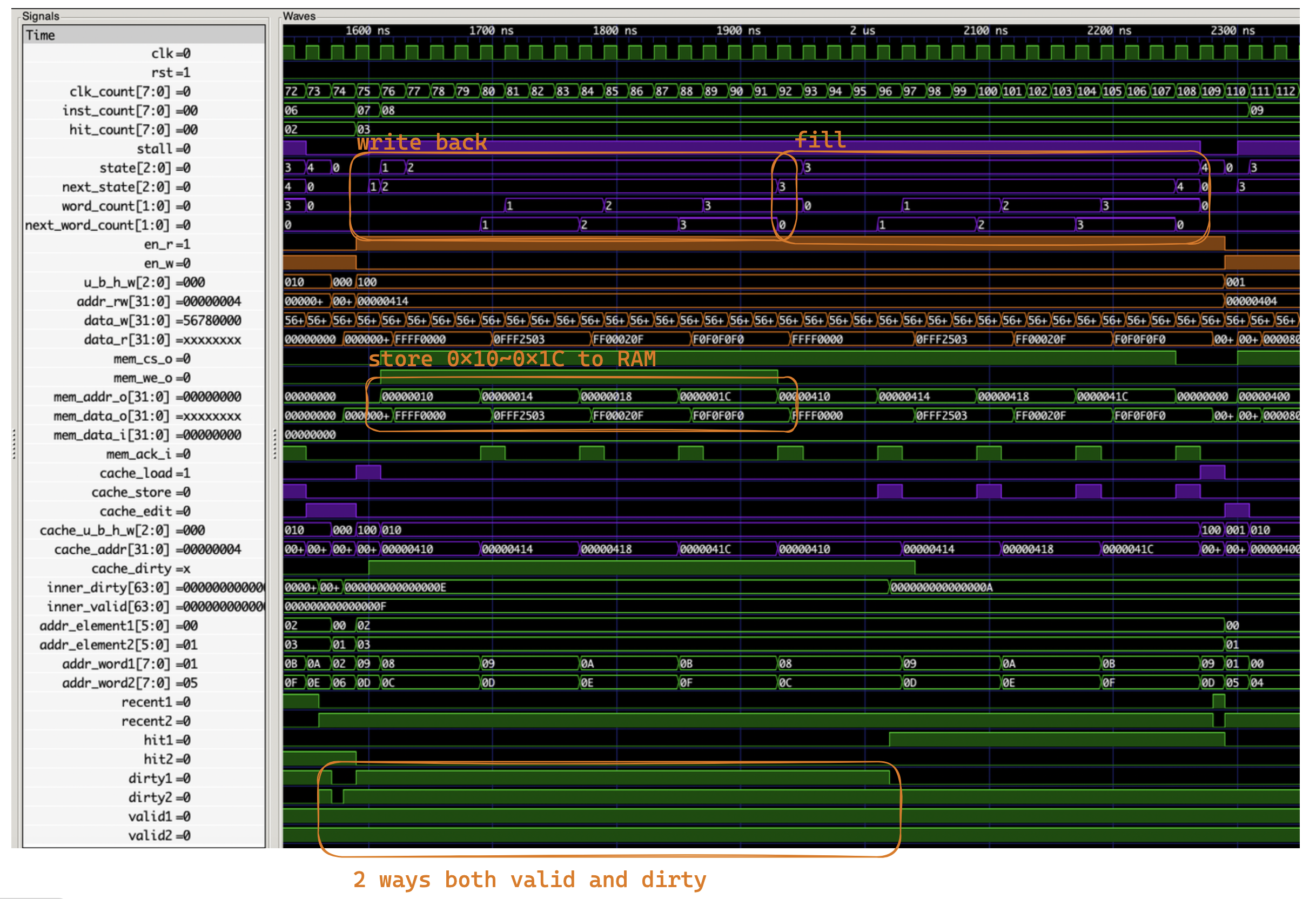
因为检测到了 miss 而且 dirty,所以 next_state 变为了 S_PRE_BACK,一个周期后变为了 S_BACK,先写回了原来位于第零组第一路的缓存数据,然后写入了新的数据。消耗了 1(S_PRE_BACK)+ 4*4(S_BACK)+ 4*4(S_FILL)+ 1(S_WAIT)+ 1(S_IDLE)= 35 个周期。
hit¶
第三条和第四条是 hit:
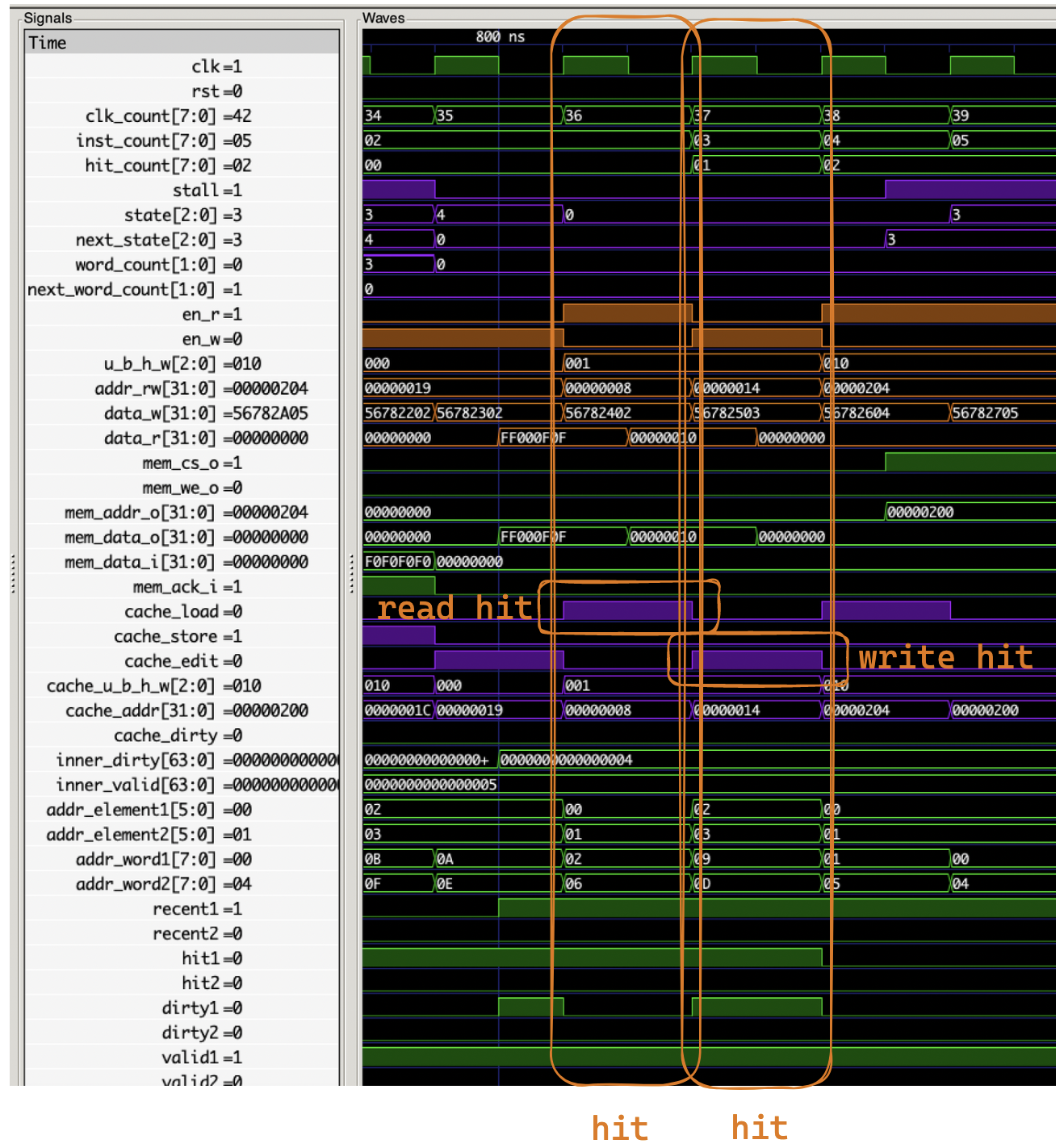
一次是 read hit 一次是 write hit,均只消耗 1 周期
Core 仿真 ¶
针对完整 CPU Core 的仿真波形如下:
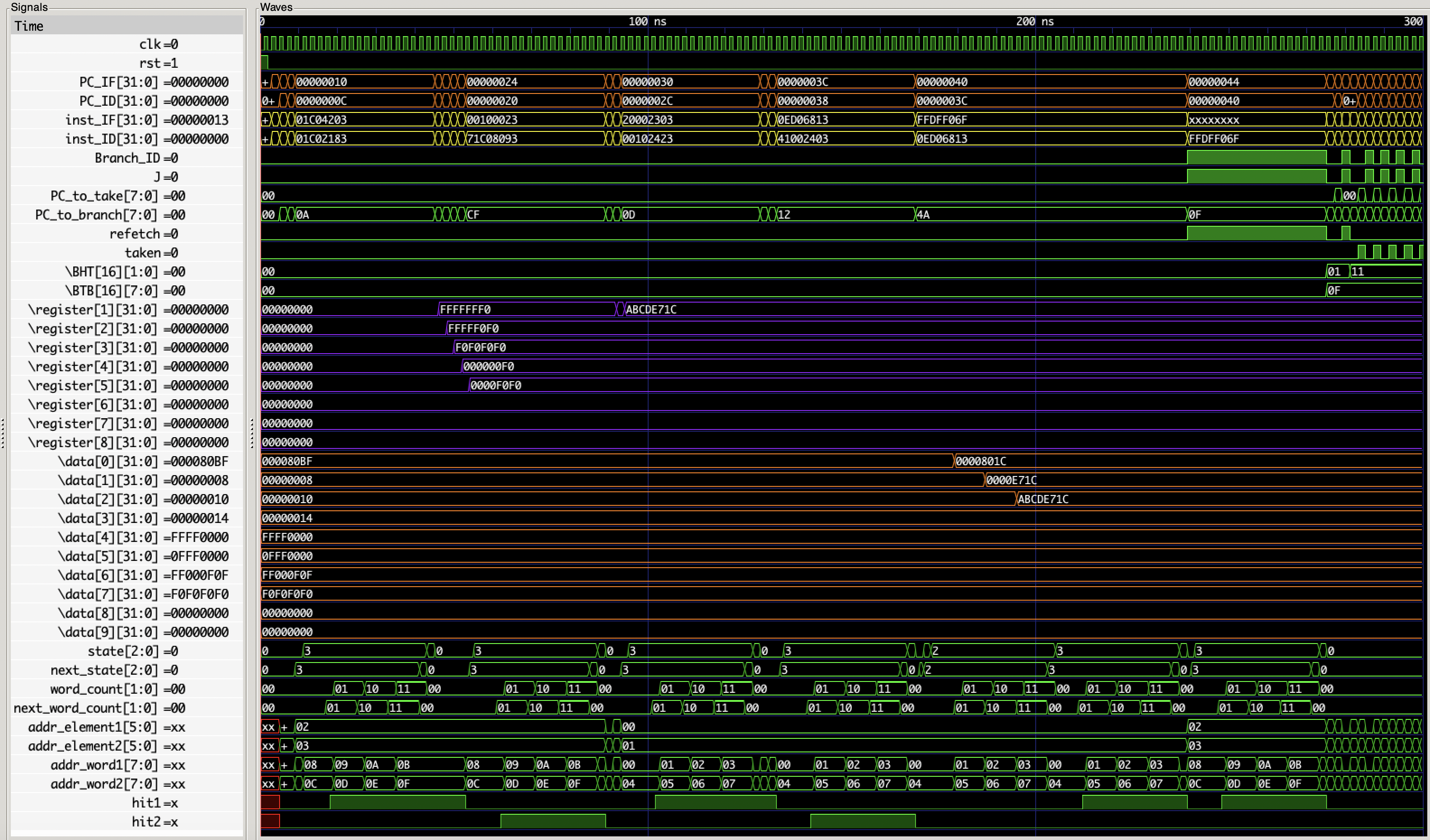
对照测试程序,第一条指令 addi 无影响,第二条指令 load miss,多消耗了 17 周期来加载缓存,接下来四条 load 均为 hit,可见这之后 x1~x5 已经变为了预期的值。接下来是 lui 和 addi 加载 x1 均只消耗一个周期。然后 store miss,加载了 0x000~0x00C,接着两条 store hit,然后一个 load miss。接下来再次 load miss,但此时有脏数据,所以先进行了写回,可以发现这时候 RAM 的数据发生了更新(因为前面的三条 store
上板验证 ¶
上板测试一切正常。
思考题 ¶
- 给出本实验给定要求下地址分割情况简图,要求有简要的计算过程

这个框架里就有给,也不太清楚到底这个思考题要干什么,有什么需要计算的。
非要说点什么的话,后两个字节是用来针对 half word / byte 读取的,所以是 log2(4) = 2 宽度,接下来是每个 cache line 里四个 32 位数据的索引,所以宽度也是 log2(4) = 2。接下来是二路组相连结构中针对组的索引,一共 64 个单元,分为两路,所以是 32 组,宽度为 log2(32) = 5。最后剩下的 23 位全是 tag。这些在前面也都分析过啊其实……
- 请分析本实验的测试代码中每条访存指令的命中 / 缺失情况,如果发生缺失,请判断其缓存缺失的类别
实验测试代码即 mem_test.s,里面注释已经分析过了吧,那这里再写一下:
- 1: lb x1, 0x01C(x0):读 miss,将 0x010~0x01C 数据写入第一组第一路
- 2、3、4、5:四次以不同形式读取 0x01C(x0),全部 hit
- 6: lw x0, 0x210(x0):读 miss,将 0x210~0x21C 数据写入第一组第二路
- 7、8 不是访存指令
- 9: sb x1, 0x0(x0):写 miss,先将 0x000~0x00C 数据写入第零组第一路,然后修改数据(标记为脏)
- 10、11:两次写入上面读过的缓存,均 hit,均修改数据(标记为脏)
- 12: lw x6, 0x200(x0):读 miss,将 0x200~0x20C 数据写入第零组第二路
- 13: lw x7, 0x400(x0):读 miss,想要写入第零组第一路,但该路已经占用且为脏,所以先将 0x000~0x00C 数据写回内存,然后将 0x400~0x40C 数据写入第零组第一路
- 14: lw x8, 0x410(x0):读 miss,想要写入第一组第一路,该路被占用但不脏,所以直接将 0x410~0x41C 数据写入第一组第一路覆盖
- 在实验报告分别展示缓存命中、不命中的波形,分析时延差异
波形分析见上,都有分析过。