Hackergame 2021 Writeup¶
约 9370 个字 286 行代码 38 张图片 预计阅读时间 35 分钟
Abstract
参加的第一个可以算是 CTF 的比赛。这里是我做出的题的 writeup,博客版在:https://blog.tonycrane.cc/p/c05d7b7c.html
签到 ¶
为了能让大家顺利签到,命题组把每一秒的 flag 都记录下来制成了日记本的一页。你只需要打开日记,翻到 Hackergame 2021 比赛进行期间的任何一页就能得到 flag!
很明确,进入网址后一直点 Next 翻到比赛时间就好了(误
看到了 URI 里有 ?page=...,所以也懒得计算了,手动二分,大概 ?page=1635000000 左右就可以看到 flag 了
赛后才反应过来原来是 UNIX 时间戳
进制十六——参上 ¶
 也很明确,直接把右侧挡住的 flag 部分对应左边的十六进制数换算成十进制,然后根据 ASCII 码转成字符。或者直接把左侧抄进 Hex Friend 也可以直接得到右侧的flag。
也很明确,直接把右侧挡住的 flag 部分对应左边的十六进制数换算成十进制,然后根据 ASCII 码转成字符。或者直接把左侧抄进 Hex Friend 也可以直接得到右侧的flag。
(** 当时这题抄串行了两三次……)
去吧!追寻自由的电波 ¶
当然,如果只是这样还远远不够。遵依史称“老爹”的上古先贤的至理名言,必须要“用魔法打败魔法”。X 同学向上级申请到了科大西区同步辐射实验室设备的使用权限,以此打通次元空间,借助到另一个平行宇宙中 Z 同学的法力进行数据对冲,方才于乱中搏得一丝机会,将 flag 用无线电的形式发射了出去。
考虑到信息的鲁棒性,X 同学使用了无线电中惯用的方法来区分字符串中读音相近的字母。即使如此,打破次元的强大能量扭曲了时空,使得最终接受到的录音的速度有所改变。
(这题在群里看起来好像卡了很多人,不知道为什么)
题目下载下来是一个听起来杂乱的音频
题里最后说了 “最终接受到的录音的速度有所改变”,所以考虑将音频时间拉长。
最开始使用了 Adobe Audition,但是效果不是很理想,大概是重新采样等一系列算法导致的
所以换了 Adobe Premier Pro 直接用比率拉伸工具拉长音频,还是可以听清的
不断尝试之后,大概放慢三倍左右就可以听出读的是英语单词了
题里说到了 “考虑到信息的鲁棒性,X 同学使用了无线电中惯用的方法来区分字符串中读音相近的字母”,所以就查到了国际航空无线电通讯 26 个英文字母读法
然后仔细听,辨别每个单词的第一个音就可以得到 flag 了
猫咪问答 Pro Max ¶
五道刁钻的题目,但是还是好查到的,题目里也说了“解出谜题不需要是科大在校学生”
- 2017 年,中科大信息安全俱乐部(SEC@USTC)并入中科大 Linux 用户协会(USTCLUG
) 。目前,信息安全俱乐部的域名(sec.ustc.edu.cn)已经无法访问,但你能找到信息安全俱乐部的社团章程在哪一天的会员代表大会上通过的吗?
看到了 “目前,已经无法访问” 说明这个域名曾经是可以访问的,直接通过 互联网的记忆 archive.org,查到这个域名的历史存档,随便找一天就可以看到他们官网中的信息安全俱乐部社团章程。
其中第一行就写了 “本章程在 2015 年 5 月 4 日,经会员代表大会审议通过
所以答案就是 20150504
- 中国科学技术大学 Linux 用户协会在近五年多少次被评为校五星级社团?
直接去科大 LUG 官网的 Intro 页面,就可以看到 “于 2015 年 5 月、2017 年 7 月、2018 年 9 月、2019 年 8 月及 2020 年 9 月被评为中国科学技术大学五星级学生社团
所以是4次(x
但是怀疑一下为什么没有2021年,因为都是在9月份左右,所以可能是数据没更新,这题4和5都有可能
尝试后得到答案是 5
- 中国科学技术大学 Linux 用户协会位于西区图书馆的活动室门口的牌子上“LUG @ USTC”下方的小字是?
这题也简单,直接问科大同学就好了(x
翻了 LUG 的微信公众号和 QQ 官方号,都没啥收获,最后发现官网上有 News。这样的话,如果新启用活动室的话,一定会有一篇新闻稿,搜索“图书馆”得到了「西区图书馆新活动室启用」这篇文章,开篇第一张大图就是门口牌子的照片
所以答案是 Development Team of Library (注意大小写)
- 在 SIGBOVIK 2021 的一篇关于二进制 Newcomb-Benford 定律的论文中,作者一共展示了多少个数据集对其理论结果进行验证?
应该没必要搜谷歌学术之类的,直接必应查 “SIGBOVIK Newcomb-Benford” 就可以找到 SIGBOVIK 的这一篇大文章合集,再搜索 Newcomb 就可以看到题目里说的论文了。
全文也不长,只有四页,后两页全是数据的图,数一下,一共有13幅
所以答案是 13
- 不严格遵循协议规范的操作着实令人生厌,好在 IETF 于 2021 年成立了 Protocol Police 以监督并惩戒所有违背 RFC 文档的行为个体。假如你发现了某位同学可能违反了协议规范,根据 Protocol Police 相关文档中规定的举报方法,你应该将你的举报信发往何处?
没啥好说的,直接查,答案 /dev/null
然后提交就可以得到 flag
卖瓜 ¶
题目里比较重要的话就是:
补充说明:当称的数字变为浮点数而不是整数时,HQ 不会认可最终的称重结果。
题目的目的也很明确,用一堆 9 和一堆 6 加起来得到 20。肯定不能 像华强一样 劈瓜,所以输入一定是整数
那就可以考虑溢出
但是经过尝试,给的数字太大,就会使结果溢出到浮点数,这不是想要的(因为即使凑到了20.0也不正确)
那如果数字再大呢,比如 2000000000000000000(18 个 0)个 9 斤的瓜,可以发现,这时直接溢出到了负整型 -446744073709551616
再补上 49638230412172000 个9斤的瓜就可以得到 -3616,加上20可以被6整除,所以再加上606个6斤的瓜就可以得到 20
恭喜你逃过一劫!华强~华强!
透明的文件 ¶
一个透明的文件,用于在终端中展示一个五颜六色的 flag。
可能是在 cmd.exe 等劣质终端中被长期使用的原因,这个文件失去了一些重要成分,变成了一堆乱码,也不会再显示出 flag 了。
注意:flag 内部的字符全部为小写字母。
拿到文件,看到里面好多 [ ; m 之类的,再结合终端中输出带颜色文字的 \033[...m; 之类的方法,以及题目中的 “失去了一些重要成分”
所以直接尝试把 [ 全局替换为 \033[,然后复制到 python 中 print,就可以看到神奇的一幕了(其实并没完全做完,但是可以已经看了)
![]() 然后读出 flag 即可(全是小写字母)
然后读出 flag 即可(全是小写字母)
旅行照片 ¶
你的学长决定来一场说走就走的旅行。通过他发给你的照片来看,他应该是在酒店住下了。
从照片来看,酒店似乎在小区的一栋高楼里,附近还有一家 KFC 分店。突然,你意识到照片里透露出来的信息比表面上看起来的要多。
请观察照片并答对全部 5 道题以获取 flag。注意:图片未在其他地方公开发布过,也未采取任何隐写措施(通过手机拍摄屏幕亦可答题
) 。

“手机拍摄屏幕亦可答题”,所以照片中没有任何地址的元信息,只能靠看图
线索:海边、KFC、高楼、大石头、停车位
先看那个 KFC,大概是个网红店,所以搜索 “网红 海边 KFC”,查到了秦皇岛,而且也是海边
再进一步看地图和街景地图就可以确定地点在 秦皇岛新澳海底世界
然后是 5 个问题
该照片拍摄者的面朝方向为:
根据地图,对比一下就可以得到,面朝方向是 东南
该照片的拍摄时间大致为:
根据选项里的时间,下午是两点半左右,而在东北的两点半左右其实和中午差不多,影子和光温也不太像这个样子,所以可以确定时间大致是 傍晚
该照片的拍摄者所在楼层为:
不好确定,但是答案可以交很多次,所以从 9 层左右依次试就可以了,最后得到楼层是 14
该照片左上角 KFC 分店的电话号码是:
直接用地图软件搜 “秦皇岛新澳 KFC” 就可以查到那家店铺,也给了电话,或者搜索 ”网红 海边 KFC“ 也可以直接得到电话:0335-7168800
该照片左上角 KFC 分店左侧建筑有三个水平排列的汉字,它们是:
通过街景地图就可以看到 KFC 左边的建筑上写了 海豚馆
FLAG 助力大红包 ¶
参与活动,助力抽奖!集满 1 个 flag,即可提取 1 个 flag。
恭喜你积攒到 0.5…… 个 flag, 剩余时间:10分00秒
已有 0 位好友为您助力。
将如下链接分享给好友,可以获得好友助力,获得更多 flag:……
老并夕夕了,经过一些测试和看规则可以知道,ip 在同一 /8 网段的用户被视为同一用户,即 ip 地址的第一个点前面的数字不一样才是不同用户
再用虚拟机和手机试一下,发现每个用户增加的 flag 数量很小
所以推测需要200+个 ip 地址,肯定不会要真的转发,而且也很难凑出很多不在同一 /8 网段的 ip
于是在 BurpSuite 里面抓包可以看到,每次点击“助力”都会发送一个到助力链接的 POST,内容为 ip 地址
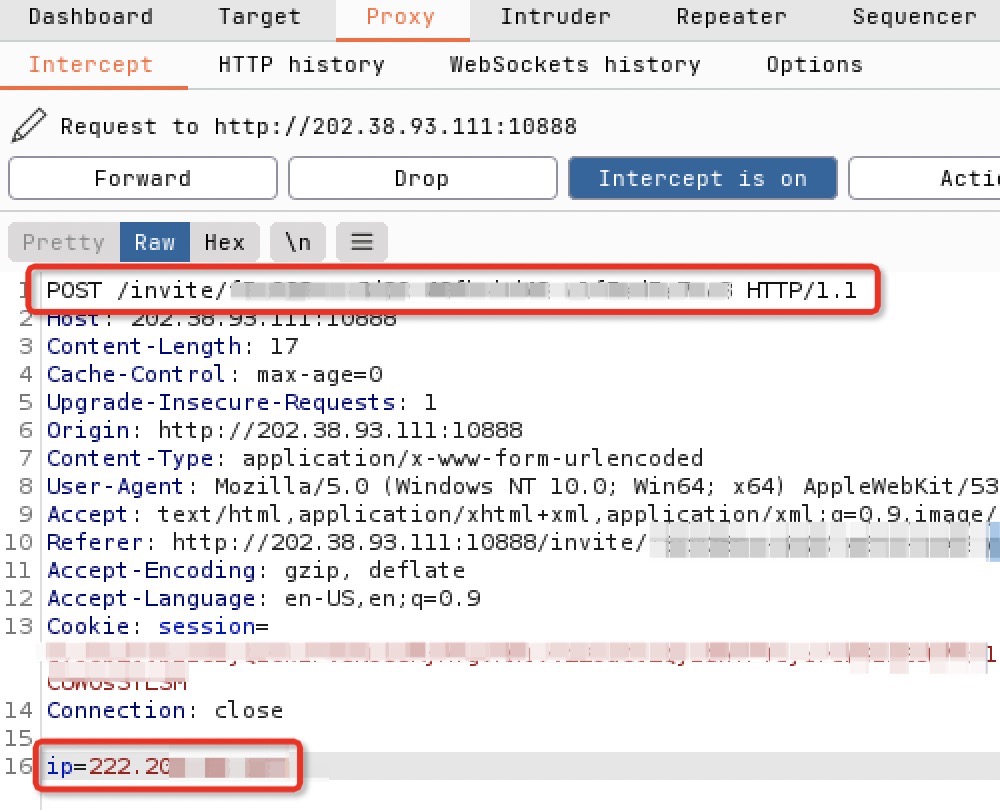 然后将其发送到 Repeater 中,尝试更改 ip 地址,得到的 Response 中说 “失败!检测到前后端检测 IPv4 地址不匹配”
然后将其发送到 Repeater 中,尝试更改 ip 地址,得到的 Response 中说 “失败!检测到前后端检测 IPv4 地址不匹配”
所以仅仅更改 POST 内容的 ip 是不够的,而提供给检测的内容也仅仅是一个 POST,所以可以更改 POST 头,添加 X-Forwarded-For
然后使用 python 就可以循环发送 POST 并伪造 ip 地址得到256个助力了,刚好达到1个flag:
(要注意 sleep 一段时间,不然会出现操作过快拒绝的情况;也不要 sleep 过长,否则超过10分钟 flag 就无效了)
import requests
import time
from tqdm import tqdm
url = "http://202.38.93.111:10888/invite/..."
with tqdm(total=256) as pbar:
for i in range(256):
res = requests.post(url, data={"ip": f"{i}.0.0.0"}, headers={"X-Forwarded-For": f"{i}.0.0.0"})
if "成功" not in res.text:
print("[x] 失败")
print(res.text)
time.sleep(1.5)
pbar.update(1)
Amnesia¶
轻度失忆 ¶
你的程序只需要输出字符串 Hello, world!(结尾有无换行均可)并正常结束。
编译指令:
gcc -O file.c -m32运行指令:
./a.out编译后 ELF 文件的 .data 和 .rodata 段会被清零。
ELF(Executable and Linkable Format)是 Linux 下常用的可执行文件格式,其中有很多不同的节:
.text节:程序运行需要的代码.data节:存放可修改的数据,一般是非 const 全局变量和静态变量.rodata节:即 read only data,一般是常量或者字符串.bss节:没有被初始化的变量- ……
而这道题目则是在编译生成可执行文件 a.out 后,清空 .data 和 .rodata
首先不妨正常编写一个输出 “Hello, world!” 的程序:
 可以发现,此时的 "Hello, world!" 被放到了 .rodata 节中,会被清除掉,所以这样写不行
可以发现,此时的 "Hello, world!" 被放到了 .rodata 节中,会被清除掉,所以这样写不行
直接使用字符串会被放到 .rodata 中清除,写成全局变量又会放到 .data 中
但是,如果写成局部变量呢:
 可以看出,这次的字符串直接写到了 .text 节中,删掉了 .data .rodata 也没有影响
可以看出,这次的字符串直接写到了 .text 节中,删掉了 .data .rodata 也没有影响所以把这个代码交上去就可以输出 “Hello, world!“ 拿到 flag 了
清除记忆直接把 .text 节全删掉了,想了很久也不知道咋搞,虽然可以 __attribute__ ((section ("..."))) 来把函数或变量塞到指定的节中。但还是不清楚要怎么解决段错误的问题 qwq
图之上的信息 ¶
小 T 听说 GraphQL 是一种特别的 API 设计模式,也是 RESTful API 的有力竞争者,所以他写了个小网站来实验这项技术。
你能通过这个全新的接口,获取到没有公开出来的管理员的邮箱地址吗?
题目信息给的很充分,用的是 GraphQL,要用其得到 admin 的邮箱
没接触过 GraphQL,所以直接必应(逃
查到了很多有用的东西:
- GraphQL 官网:了解一下 GraphQL 是干什么的,要怎么用
- GraphiQL:一个进行 GraphQL 查询的 GUI
- 【安全记录】玩转 GraphQL - DVGA 靶场(上)- 知乎
- GraphQL Voyager:可视化现实 GraphQL 内省出的结构
简而言之,GraphQL 就是一个可以通过一次 query 请求查询多个资源的 API 模式,只要 网址/graphql?query=... 就可以实现查询
有些使用 GraphQL 的网站可以直接通过访问 网址/graphiql 得到查询的 GUI
但是本题中禁止了,但可以使用 GraphiQL 软件来进行查询
在第三个链接中可以了解到,可以利用 GraphQL 的内省查询来泄露出内部的结构,把其中的查询语句丢到 GraphiQL 中可以得到结果
query IntrospectionQuery { __schema { queryType { name } mutationType { name } subscriptionType { name } types { ...FullType } directives { name description locations args { ...InputValue } } }}fragment FullType on __Type { kind name description fields(includeDeprecated: true) { name description args { ...InputValue } type { ...TypeRef } isDeprecated deprecationReason } inputFields { ...InputValue } interfaces { ...TypeRef } enumValues(includeDeprecated: true) { name description isDeprecated deprecationReason } possibleTypes { ...TypeRef }}fragment InputValue on __InputValue { name description type { ...TypeRef } defaultValue}fragment TypeRef on __Type { kind name ofType { kind name ofType { kind name ofType { kind name ofType { kind name ofType { kind name ofType { kind name ofType { kind name } } } } } } }}

然后把结果丢到 GraphQL Voyager 中就可以得到可视化的结构:
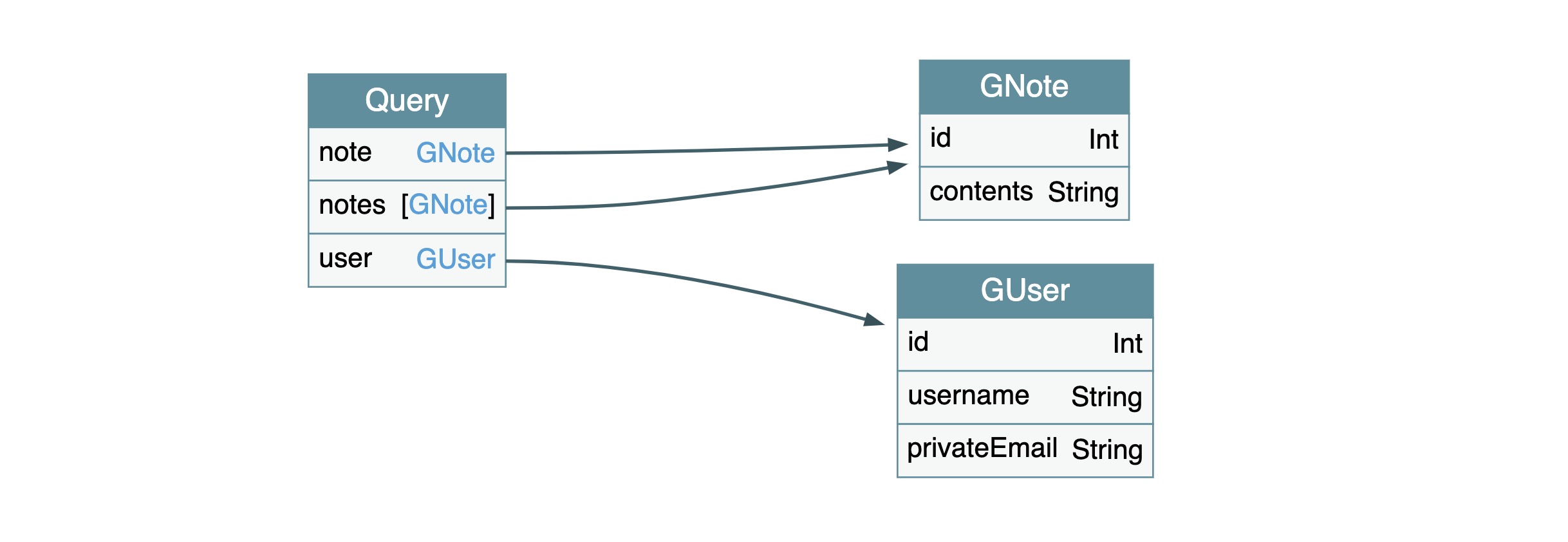
所以只需要根据 id query 一下 user 就可以了:
Easy RSA¶
自从 Hackergame 2018 公然揭露了大整数可以被神童口算分解的事实,RSA 在 hackergame 中已经只能处于低分值的地位了。如果不在其名称前面加上 Easy 这个单词,似乎就会显得完全对不起其他题目。
更何况,在本题的附件中,你还获得了构造 p 和 q 的方式。数理基础扎实的你应该可以轻松解决这些问题吧。
谢邀,没有数理基础
看代码!
e = 65537
def get_p():
x = 11124440021748127159092076861405454814981575144744508857178576572929321435002942998531420985771090167262256877805902135304112271641074498386662361391760451
y = 11124440021748127159092076861405454814981575144744508857178576572929321435002942998531420985771090167262256877805902135304112271641074498386662361391661439
value_p = sympy.nextprime((math.factorial(y)) % x) # Hint:这里直接计算会溢出,请你仔细观察 x 和 y 的特征
return value_p
def get_q():
value = [getPrime(256)]
for i in range(1, 10):
value.append(sympy.nextprime(value[i - 1]))
print("value[-1] = ", value[-1])
# value[-1] = 80096058210213458444437404275177554701604739094679033012396452382975889905967
n = 1
for i in range(10):
n = n * value[i]
q = getPrime(512)
value_q = pow(q, e, n)
print("value_q = ", value_q)
# value_q = 5591130088089053683141520294620171646179623062803708281023766040254675625012293743465254007970358536660934858789388093688621793201658889399155357407224541324547522479617669812322262372851929223461622559971534394847970366311206823328200747893961649255426063204482192349202005330622561575868946656570678176047822163692259375233925446556338917358118222905050574458037965803154233167594946713038301249145097770337253930655681648299249481985768272321820718607757023350742647019762122572886601905212830744868048802864679734428398229280780215896045509020793530842541217790352661324630048261329493088812057300480085895399922301827190211956061083460036781018660201163819104150988531352228650991733072010425499238731811243310625701946882701082178190402011133439065106720309788819
return sympy.nextprime(q)
# this destroyes the rsa cryptosystem
p = get_p()
q = get_q()
m = int.from_bytes(open("flag.txt", "rb").read(), "big")
c = pow(m, e, p * q)
print("c = ", c)
# c = 110644875422336073350488613774418819991169603750711465190260581119043921549811353108399064284589038384540018965816137286856268590507418636799746759551009749004176545414118128330198437101472882906564195341277423007542422286760940374859966152871273887950174522820162832774361714668826122465471705166574184367478
get_p() 中 y! % x 溢出的问题,以及 get_q() 中 q 是哪个随机的512位质数的问题
get_p:
代码里也给了 Hint,观察 x 和 y 的特征。x 和 y 都很大,但是两个的差并不大;而且可以丢到 python 里验证出 x 是一个质数
所以可以使用威尔逊定理
也查到了威尔逊定理在 RSA 题目中的应用:BUU-RSA [RoarCTF2019]babyRSA
要求 y! % x(x 是质数)
根据威尔逊定理,有
所以:
令 \(k = \dfrac{(x - 1)!}{y!} = (y+1)(y+2)...(x-1)x\) ,所以有:
(其中 \(\mathrm{inv}(k, x)\) 表示模 x 下 k 的逆元)
所以重写 get_p() 即可正确的得到 p:
def get_p():
x = ...
y = ...
k = 1
for i in range(y + 1, x):
k = (k * i) % x
res = (-gmpy2.invert(k, x)) % x
return sympy.nextprime(res)
get_q:
相比来说,get_q 就没那么需要技巧了
给出了 value[-1] 的值,所以可以直接用 sympy.prevprime 逆推出整个 value 数组
value = [80096058210213458444437404275177554701604739094679033012396452382975889905967]
for i in range(1, 10):
value.append(sympy.prevprime(value[i - 1]))
print("value[-1] = ", value[-1])
后面计算 value_q 细看其实也是一个 RSA 算法:
- q:密文
- e:私钥
- value_q:明文
- n:就是 n,只不过不是两个质数相乘,是十个质数相乘
十个质数相乘得到 n 的 RSA 算法也一样,因为 RSA 的正确性并没有要求 n 一定是两个大质数相乘,这样只是难以破解保证安全性
解决这个同样也是需要公钥 d,所以需要 phi(n)
根据欧拉函数的性质,phi(n) 等于 n 的所有质因数减一的积
即 phi(n) = (value[0] - 1) * (value[1] - 1) * ... * (value[9] - 1)
再解密即可得到密文 q,然后也就得到了 get_q 的结果
n = phi = 1
for i in range(10):
n = n * value[i]
phi *= (value[i] - 1)
value_q = ...
d = pow(e, -1, phi)
q = pow(value_q, d, n)
return sympy.nextprime(q)
flag:
搞定了 get_p 和 get_q 之后就可以直接解出 flag 了:
e = 65537
p = get_p()
q = get_q()
c = ...
d = pow(e, -1, (p-1) * (q-1))
m = pow(c, d, p * q)
print(int.to_bytes(m, 30, byteorder="big"))
加密的 U 盘 ¶
(本来挺好做的一道题,怎么题给的提示我就硬是没领会到)
这是一个关于 LUKS (Linux Unified Key Setup) 的故事。
第一天
小 T:「你要的随机过程的课件我帮你拷好了,在这个 U 盘里,LUKS 加密的密码是 suijiguocheng123123。」
小 Z:「啊,你又搞了 Linux 文件系统加密,真拿你没办法。我现在不方便用 Linux,我直接把这块盘做成磁盘镜像文件再回去处理吧。」第二天
小 Z:「谢谢你昨天帮我拷的课件。你每次都搞这个加密,它真的安全吗?」
小 T:「当然了!你看,你还给我之后,我已经把这块盘的弱密码改掉了,现在是随机生成的强密码,这样除了我自己,世界上任何人都无法解密它了。」
小 Z:「我可不信。」
小 T:「你不信?你看,我现在往 U 盘里放一个 flag 文件,然后这个 U 盘就给你了,你绝对解密不出来这个文件的内容。当初搞 LUKS 的时候我可研究了好几天,班上可没人比我更懂加密!」
一共给了两个 img 文件,通过 file 可以看出都是 DOS/MBR boot sector
$ file *.img
day1.img: DOS/MBR boot sector; partition 1 : ID=0xee, start-CHS (0x0,0,2), end-CHS (0x3ff,255,63), startsector 1, 40959 sectors, extended partition table (last)
day2.img: DOS/MBR boot sector; partition 1 : ID=0xee, start-CHS (0x0,0,2), end-CHS (0x3ff,255,63), startsector 1, 40959 sectors, extended partition table (last)
$ file *.img
My Disk.img: LUKS encrypted file, ver 2 [, , sha256] UUID: e9a660d5-4a91-4dca-bda5-3f6a49eea998
My Disk 2.img: LUKS encrypted file, ver 2 [, , sha256] UUID: e9a660d5-4a91-4dca-bda5-3f6a49eea998
在 Kali Linux 里尝试直接挂载第一个 img,要求输入密码,把题给的密码输入就可以看到 “课件”
以上都是已知的试验部分,真正要做的是解开第二个未知密码的 LUKS img
已知磁盘的加密使用的是 luks2,在网上查了破解 luks2 之类的都说 luks2 不可破解,或者是使用已知的密码字典来爆破
但是题里说了 “随机生成的强密码”,所以也是没有密码字典的
其实这道题的最大提示就在于它给了两个 img,既然第一个 img 打开后仅仅是一个课件,如果它的用处仅仅是用来试验 luks 怎么打开的话,根本它没必要给出
所以第一个 img 肯定还是有用的。
再看题目,反复说了 U 盘,所以这两个 img 应该是同一个 U 盘的镜像文件,只是更改了密码而已(file 看到的 uuid 也是一致的)
于是继续必应,发现同一个磁盘的 master-key 是一样的,而且可以用 master-key 来添加密码恢复磁盘(见:10 Linux cryptsetup Examples for LUKS Key Management)
所以就跟着文章里的做法,从第一个 img 中提取出 master-key,然后用它来提供 AddKey 的权限。添加了新 passphrase 后就可以用新密码打开磁盘了:
$ cryptsetup luksDump --dump-master-key MyDisk.img # 输出 master-key
...
MK dump: be 97 db 91 5c 30 47 ce 1c 59 c5 c0 8c 75 3c 40
72 35 85 9d fe 49 c0 52 c4 f5 26 60 af 3e d4 2c
ec a3 60 53 aa 96 70 4d f3 f2 ff 56 8f 49 a1 82
60 18 7c 58 d7 6a ec e8 00 c1 90 c1 88 43 f8 9a
$ cat "be...9a" > master_key.txt # 存入文件
$ xxd -r -p master_key.txt master_key.bin # 转为二进制
$ cryptsetup luksAddKey MyDisk2.img --master-key-file <(cat master_key.bin) # 添加密码
Enter new passphrase for key slot: # 输入新密码即可,因为master-key-file相当于提供了原始密码
Verify passphrase:
然后挂载、输入密码,就可以看到 flag.txt 了
赛博厨房 ¶
虽然这是你的餐厅,但只有机器人可以在厨房工作。机器人精确地按照程序工作,在厨房中移动,从物品源取出食材,按照菜谱的顺序把食材依次放入锅内。
机器人不需要休息,只需要一个晚上的时间来学习你教给它的程序,在此之后你就可以在任何时候让机器人执行这个程序,程序的每一步执行都会被记录下来,方便你检查机器人做菜的过程。
另外为了符合食品安全法的要求,赛博厨房中的机器人同一时间手里只能拿一种食物,每次做菜前都必须执行清理厨房的操作,把各处的食物残渣清理掉,然后回到厨房角落待命。
每天的菜谱可能不同,但也许也存在一些规律。
对机器人编程可以使用的指令有(n, m 为整数参数,程序的行号从 0 开始,注意指令中需要正确使用空格
) :向上 n 步
向下 n 步
向左 n 步
向右 n 步
放下 n 个物品
拿起 n 个物品
放下盘子
拿起盘子
如果手上的物品大于等于 n 向上跳转 m 行
如果手上的物品大于等于 n 向下跳转 m 行赶紧进入赛博厨房开始做菜吧!
刚看题还是挺懵的,想了好半天才明白
简单说来就是,每天可以编写新的程序,但是只能运行一个之前编写过的程序
每个程序只有几种指令可以使用,需要在其中满足菜谱的顺序要求
而问题在于,编写程序后的第二天的菜谱可能会不同,导致前面编写的程序无法使用
所以就需要预测第二天的菜谱
Level 0¶
可以看到第 0 天的菜谱是 1, 0,也就是要在同一个程序中依次向锅 (1,0) 中放入 1 号食物 (0,2) 和 0 号食物 (0,1)
随便编写程序保存,直接到下一天,可以发现菜谱发生了变化
多次尝试之后发现菜谱只有 0,0 / 0,1 / 1,0 / 1,1 四种
所以在第 0 天编写学习四个程序,到下一天就可以根据菜谱来执行了
例如程序 1,0 就可以编写为:
Level 1¶
只有 1 个食物,菜谱是好多 0
同样随便编写程序保存进入下一天,发现菜谱没有变化,还是 73 个 0
所以这一关可能只是循环的教程
可用的指令中有一条 “如果手上的物品大于等于 n 向上跳转 m 行”
可以用它来达到循环的效果
只需要拿 73 个物品,然后循环放下直到手中没有了即可
同样保存下一天执行就可以拿到 flag 了剩下的两个看起来大概是通过源码来推测出菜谱的生成方法,然后编写相应的指令,太难了,不会 qwq
Micro World¶
宇宙中某一片极其微小的区域里的粒子被一股神秘力量初始化设置成了 flag 的形状,程序忠实地记录了一段时间之后这片区域的粒子运动情况。
拿到了 exe 文件,看起来挺精致,运行起来是一些点运动碰撞的场景
拖到 IDA 里看看,发现了 __main__ 以及 .rdata 里一些 py 有关的字符串:
 所以推测是使用 python 编写的,然后用 pyinstaller 打包
所以推测是使用 python 编写的,然后用 pyinstaller 打包
这样的话试着用 pyinstxtractor 解包 .exe,成功得到一个文件夹
里面是一堆 .pyc .pyd .dll 文件,从名字就可以看出大部分是 import 的包,只有一个特别的 2.pyc
所以这个应该就是编译后的源码了
接下来用 uncompyle6 来反编译 pyc 文件,输出得到了源码 2.py
尝试运行,发现跑起来之后只有一个点在运动,应该是反编译时出了些问题
于是开始看源码
基本上简单说就是,初始有一些数据,表示每个点的位置和速度,然后运行,每次运行都检测碰撞,然后获得新的点位置,再绘制出来
调试一下,输出每次的 pointlist,发现第一次是所有点,第二次变成2个,第三次往后就只有一个了
所以问题大概就出在了 next_pos_list 函数:
def next_pos_list(Pointlist):
pointlist = []
for i in range(len(Pointlist)):
for point in Pointlist[i + 1:]:
times = checkcrush(Pointlist[i], point)
if times != None:
a, b = get_new_point(times, Pointlist[i], point)
pointlist.extend([a, b])
Pointlist[i].flag = 0
point.flag = 0
else:
for item in Pointlist:
if item.flag != 0:
pointlist.append(Point((item.x + item.vx, item.y + item.vy), item.vx, item.vy))
for poi in pointlist:
poi.x = poi.x % WIDTH
poi.y = poi.y % HEIGHT
else:
return pointlist
def next_pos_list(Pointlist):
pointlist = []
for i in range(len(Pointlist)):
for point in Pointlist[i + 1:]:
...
for item in Pointlist:
...
return pointlist
但是画面仍然是杂乱的。因为题里说了 “记录了一段时间之后这片区域的粒子运动情况”
所以需要将轨迹往前推,最方便的方法就是更改每个点的速度方向:
 虽然不太清晰,但是也可以猜个大概
虽然不太清晰,但是也可以猜个大概
阵列恢复大师 ¶
(这题整整做了我两天多,每天晚上都对着磁盘阵列……)
以下是两个压缩包,分别是一个 RAID 0 阵列的磁盘压缩包,和一个 RAID 5 阵列的磁盘压缩包,对应本题的两小问。你需要解析得到正确完整的磁盘阵列,挂载第一个分区后在该分区根目录下使用 Python 3.7 或以上版本执行 getflag.py 脚本以获取 flag。磁盘数据保证无损坏。
RAID 5¶
虽然 RAID 5 是第二问,而且分数高,但是更好做,而且做出的人也多。
因为数据保证无损坏,所以要做的仅仅是找出五个磁盘的顺序和块大小
顺序可以先简单地看看 strings *.img 输出的内容
逐个文件看,可以发现每个文件比较靠前的地方会有一段是 git 历史记录的一部分:
 根据里面的时间可以推断出磁盘的顺序大致是:
根据里面的时间可以推断出磁盘的顺序大致是:
Qj... -> 60... -> 3R... -> Ir... -> 3D...
只是,这个顺序应该是一个环,谁在第一还没区分出来
在看每个文件的头部,只有 60... 和 3R... 有 “EFI PART”:
 所以应该是一个在开头,一个在结尾。所以最终的顺序是:
所以应该是一个在开头,一个在结尾。所以最终的顺序是:
3R... -> Ir... -> 3D... -> Qj... -> 60...
然后需要找到块大小
直接丢到 DiskGenius 里组建虚拟 RAID,选左同步,然后可以试出来当块大小是 64k 的时候正好可以拼出完整磁盘
然后克隆磁盘生成 img 文件,再挂载,进入,执行 getflag.py 就得到了 flag
RAID 0¶
在做 RAID 5 的时候还发现了一个叫 Raid Reconstructor 的软件,可以爆破 RAID 阵列顺序和块大小
所以这问也就懒得看了,直接丢给 Raid Reconstructor 来爆破,得到最推荐的顺序:
wl. -> jC. -> 1G. -> 5q. -> d3. -> eR. -> RA. -> ID.
和块大小 128k
然后直接用 Raid Reconstructor 的 Copy 导出 img 文件,提取后又得到一个新的 img 文件
通过 file 可以看到结果的文件系统是 XFS
但是始终无法挂载(搞了一天)
可能是 Raid Reconstructor 的问题,所以又用 DiskGenius 试了下
因为 win 和 DiskGenius 读不了 XFS 文件系统,所以拼起来之后直接克隆出 img 文件
然后拖到 Kali Linux 里挂载,成功挂载后进入、运行 getflag.py 就得到了 flag
助记词 ¶
题目有效内容:
你的室友终于连夜赶完了他的 Java 语言程序设计的课程大作业。看起来他使用 Java 17 写了一个保存助记词的后端,当然还有配套的前端。助记词由四个英文单词组成,每个用户最多保存 32 条。
你从他充满激情却又夹杂不清的表述中得知,他似乎还为此专门在大作业里藏了两个 flag:当访问延迟达到两个特殊的阈值时,flag 便会打印出来,届时你便可以拿着 flag 让你的室友请你吃一顿大餐。
下载到源码后翻一翻,有用的就只有 Phrase.java 和 Instance.java
其中 Phrase.java 定义了 Phrase,其中重载了 equals 方法,其中有:
try {
TimeUnit.MILLISECONDS.sleep(EQUALS_DURATION_MILLIS); // 20ms
// TODO: remove it since it is for debugging
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
而 Instance.java 的 post 方法中对于每次的输入,遍历输入的列表,然后逐个加进 HashMap 中
在加入 HashMap 的时候就涉及到判断是否相等
而最终会判断在完成前后的总的时间间隔是多少,如果大于 600ms 就提取出第一个 flag:
var modified = 0;
var before = System.nanoTime();
for (var i = 0; i < input.length() && i < MAX_PHRASES && phrases.size() < MAX_PHRASES; ++i) {
var text = input.optString(i, "").toLowerCase(Locale.ENGLISH);
modified += phrases.add(Phrase.create(this.mnemonics, text, token)) ? 1 : 0;
// 这里会 sleep
}
var after = System.nanoTime();
var duration = TimeUnit.MILLISECONDS.convert(after - before, TimeUnit.NANOSECONDS);
if (duration > FLAG1_DURATION_MILLIS) { // 600ms
token.addFlag(1, flag -> output.put("flag1", flag));
}
而在网页中添加条目的时候,一次只能添加一条,也就是一个 POST 里面只有一个 Phrase
但是源码中有一个循环,遍历整个 input,所以一个 POST 里的内容其实是一个列表
所以可以用 BurpSuite 获取 POST 然后更改一下内容再发送出去(先 random 一个,然后 add)
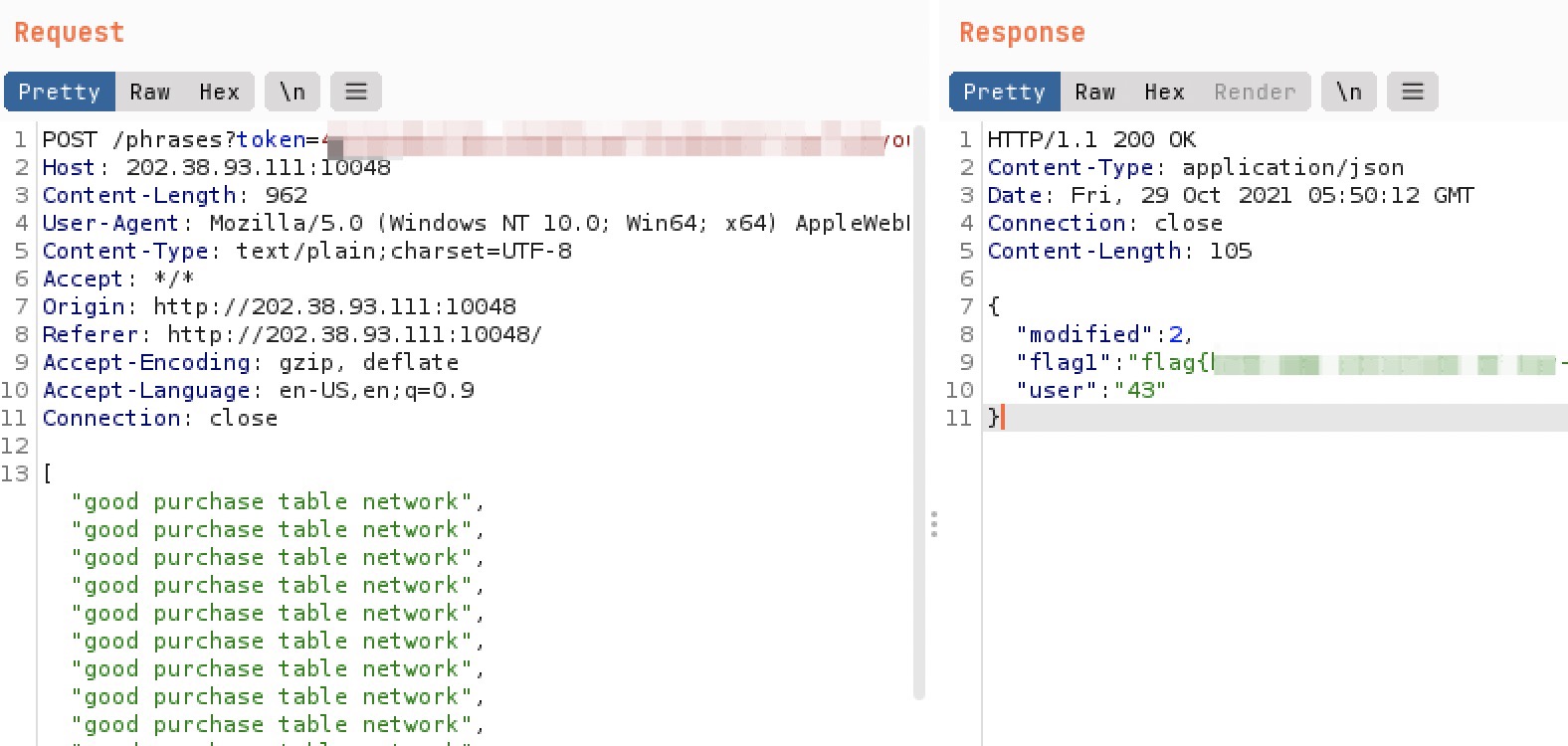 根据 flag 里的提示,正解(第二顿大餐)应该是使用哈希碰撞,
根据 flag 里的提示,正解(第二顿大餐)应该是使用哈希碰撞,但是不会
马赛克 ¶
(这道题已经做破防了,本以为是个青铜,结果是个王者……)
我做的肯定不是正解,利用二维码纠错能力勉强拿到了 flag,所以就不详细写 writeup 了,主要还是要看官方 wp(逃
大概步骤就是:
- 读图片
- 把已知的像素提取出来
- 把四个小定位块填上
- 挨个马赛克块寻找使还原的数据平均数与原马赛克值差的绝对值小于 1 的填补方法
- 如果只有一种就填上,并且标注已经填好,以后不再搜寻
- 如果有多种就先放下不填
- 重复 4 的过程,这是还会有唯一确定的填补方案。重复 4 次大概就不剩唯一解了
- 这时重复 4,找出仅有 2 中填补方法的,选误差最小的填上
- 然后再重复 4
- 然后重复 6
- 然后重复 4
- 这时可以看到已经还原得差不多了,剩下的不管直接扫码也可以扫出 flag 了

看,做法很烂对吧
minecRaft¶
kk 同学很喜欢玩 Minecraft,他最近收到了一张 MC 地图,地图里面有三盏灯,还有很多奇奇怪怪的压力板。
但他发现这些灯好像不太符合 MC 电磁学(Red stone
) ,你能帮他把灯全部点亮吗?注:本题解法与原版 Minecraft 游戏无关。
补充说明:flag 花括号内为让三盏灯全部点亮的最短的输入序列。例如,如果踩踏压力板输入的最短的序列为 abc,则答案为 flag{abc}。
还挺好玩的题,在网页中模拟了一个 mc 出来
看源码看到了引入了 flag.js 文件,所以可能就是要通过它来得到答案:
gyflagh(input) 是否为 true 来判断,而 gyflagh 也在 flag.js 中,所以还是要看 flag.js
但是 flag.js 是经过简单混淆过的,还是要费点时间读一下
其中有四个转换 Str4 Base16 和 Long 的函数可以略掉不管
注意到了 _0x381b() 这个函数里有一个列表,而且比较简单,其实它返回的就是这个列表
['encrypt', '33MGcQht', '6fbde674819a59bfa12092565b4ca2a7a11dc670c678681daf4afb6704b82f0c', '14021KbbewD', 'charCodeAt', '808heYYJt', '5DlyrGX', '552oZzIQH', 'fromCharCode', '356IjESGA', '784713mdLTBv', '2529060PvKScd', '805548mjjthm', '844848vFCypf', '4bIkkcJ', '1356853149054377', 'length', 'slice', '1720848ZSQDkr']
而且源码中只有最开头的调用匿名函数里面有
['push'] 和 ['shift'],所以推测这个匿名函数就是将这个列表循环右移两个位置那这个匿名函数也不用看了
再来看 _0x2c9e() 这个函数:
function _0x2c9e(_0x49e6ff, _0x310d40) {
const _0x381b4c = _0x381b();
return _0x2c9e = function(_0x2c9ec6, _0x2ec3bd) {
_0x2c9ec6 = _0x2c9ec6 - 0x1a6;
let _0x4769df = _0x381b4c[_0x2c9ec6];
return _0x4769df;
}
,
_0x2c9e(_0x49e6ff, _0x310d40);
}
_0x381b4c 是刚刚说的那个列表 lst。然后 return 里面重新定义了 _0x2c9e,但是新的定义里第二个参数并没有用,然后调用返回,所以整个函数就相当于:
0x1a6 是 422,所以整个函数也就相当于 function(x) { return lst[x - 422]; }同时根据第一行,程序中所有
_0x22517d 也是这个函数
然后看判断答案的 gyflagh 函数
function gyflagh(_0x111955) {
const _0x50051f = _0x22517d;
let _0x3b790d = _0x111955[_0x50051f(0x1a8)](_0x50051f(0x1b7));
if (_0x3b790d === _0x50051f(0x1aa))
return !![];
return ![];
}
function gyflagh(ans) {
if (ans["encrypt"]("1356853149054377") === "6fbde674819a59bfa12092565b4ca2a7a11dc670c678681daf4afb6704b82f0c") {
return true;
}
return false;
}
然后就可以结合 lst 中的值和索引,翻译出最重要的函数
再进行一些运算,用注释标注一下已知的值就可以得到:
String["prototype"]["encrypt"] = function(key) { // key = "1356853149054377"
const left = new Array(2);
const right = new Array(4);
let res = "";
ans = escape(this); // this := ans
right = [909456177, 825439544, 892352820, 926364468]
for (var i = 0; i < ans["length"]; i = i + 8) {
left[0] = Str4ToLong(ans["slice"](i, i + 4));
left[1] = Str4ToLong(ans["slice"](i + 4, i + 8));
code(left, right);
res = res + (LongToBase16(left[0]) + LongToBase16(left[1]));
}
return res; // 6fbde674819a59bfa12092565b4ca2a7a11dc670c678681daf4afb6704b82f0c
};
再来看 code 函数,根据 << 4、 ^、 >>> 5 可以大胆推测类似 TEA,然后解码就直接翻过来就好了:
function dec(left, right) {
for (var i = 2654435769 * 32; i != 0;) {
left[1] -= ((left[0] << 4 ^ left[0] >>> 5) + left[0] ^ i + right[i >>> 11 & 3]);
i -= 2654435769;
left[0] -= ((left[1] << 4 ^ left[1] >>> 5) + left[1] ^ i + right[i & 3]);
}
console.log(left);
}
最后把要得到的 res 分块,每 8 个一组:
然后从后往前,每两个执行 Base16ToLong,然后作为 left 传给 dec 函数解码,然后再 LongToStr4 得到四个字符: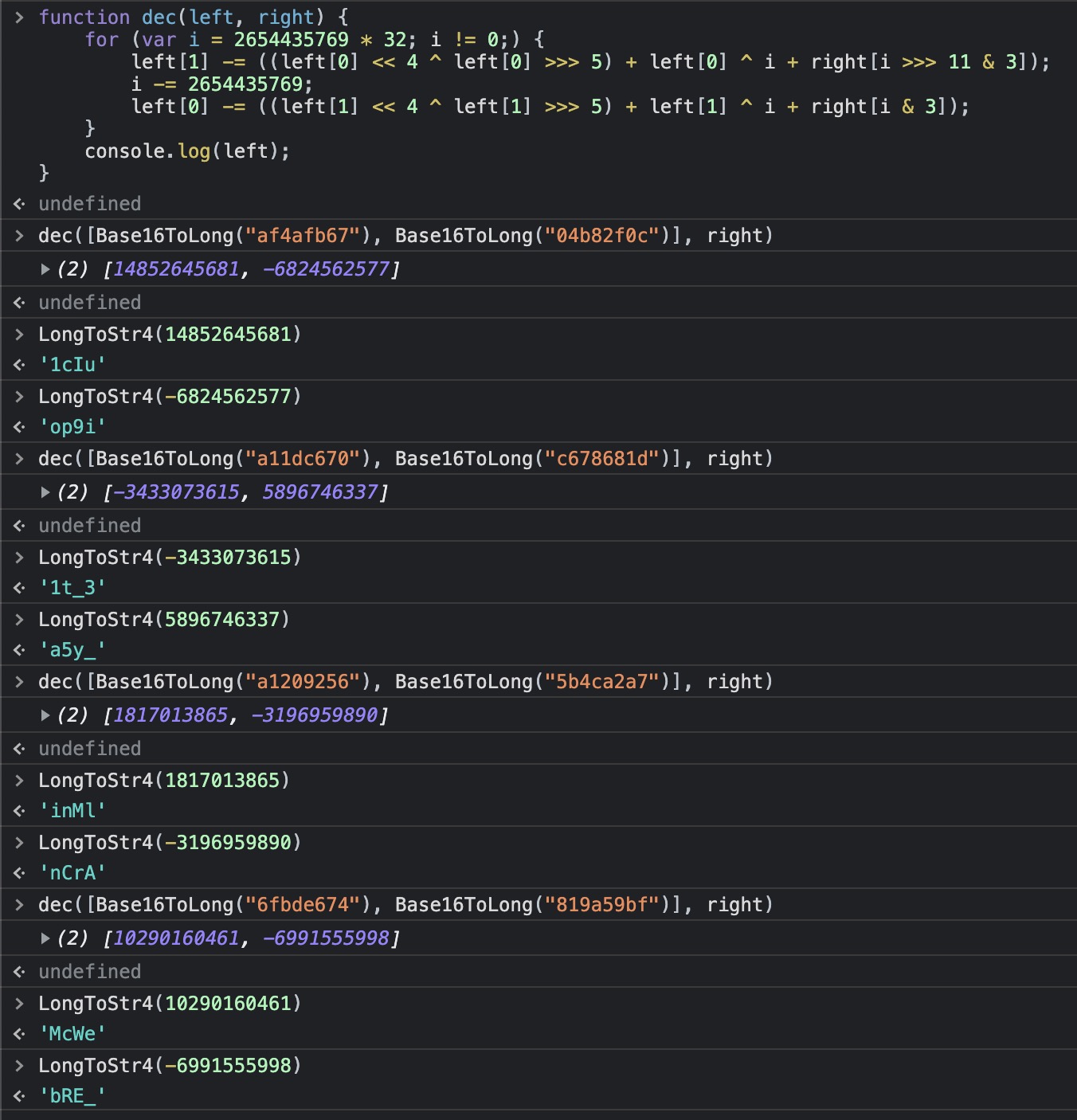 拼起来就是 flag 了:
拼起来就是 flag 了:flag{McWebRE_inMlnCrA1t_3a5y_1cIuop9i}
密码生成器 ¶
小 T 最近又写了一个 web 应用。
他发现很多用户都喜欢设置弱密码,于是决定让所有用户的密码都必须是 16 位长,并且各种符号都要有。为了让大家可以方便生成这样的密码,他还写了一个密码生成器,让用户可以生成符合规则的密码。
但这样果真安全吗?
(感觉这次 Hackergame 题的 tag 都很诡异。这题明明是 misc(general) 为什么打了 binary 的 tag)
看到 binary tag 直接先往 IDA 里面丢,然后报错了,大概是因为部分 winapi 导入不进去的问题(
然后就不会了…… 对着 IDA 干瞪眼
看题,题目给了一个网站,用来发布展板,看起来只有 admin 用户,而且没有注册系统,所以应该就是要搞到 admin 的密码了
再细看网站,特意提到 “网页显示时间”,而且展板后面都有发布时间,点进 admin 的用户页面发现也有注册时间,着实有些许诡异(
所以时间应该是一个提示
而写代码的时候设置随机数种子又常以当前时间作为种子,所以生成的密码可能是和时间有关系的
通过调系统时间,可以发现在同一秒点下生成,产生的密码是一样的
所以只需要把系统时间调到 admin 的注册时间左右,然后每秒生成密码,再挨个输进去爆破即可
最后得到 2021-09-22 23:10:53 时生成的密码 $Z=CBDL7TjHu~mEX 就是 admin 的密码
然后登录即可在“我的”里看到一条私密展板,内容是 flag
p😭q¶
学会傅里叶的一瞬间,悔恨的泪水流了下来。
当我看到音频播放器中跳动的频谱动画,月明星稀的夜晚,深邃的银河,只有天使在浅吟低唱,复杂的情感于我眼中溢出,像是沉入了雾里朦胧的海一样的温柔。
这一刻我才知道,耳机音响也就图一乐,真听音乐还得靠眼睛。
(注意:flag 花括号内是一个 12 位整数,由 0-9 数位组成,没有其它字符
。 )
虽然这题是在倒数第三题,还值 400pt,但你一说傅里叶我可就不困了嗷
下载题目包,有一个生成 gif 的 py 代码和那个 gif 文件
正好前面的电波也有一段音频,可以用那个带入到 generate_sound_visualization.py 中生成一个 gif,然后用这个来测试
再仔细看一看 generate_sound_visualization.py 这个文件
主要使用了 librosa,于是就可以翻文档来看懂这个程序:
y, sample_rate = librosa.load("flag.mp3") # 从mp3中读取数据和采样率
spectrogram = numpy.around( # 四舍五入,但会造成逆向的时候有少许误差导致杂音
librosa.power_to_db( # 把以功率为单位的频谱图转换为以分贝为单位
librosa.feature.melspectrogram( # 通过音频数据和采样率计算梅尔频谱
y, sample_rate, n_mels=num_freqs,
n_fft=fft_window_size,
hop_length=frame_step_size,
window=window_function_type
)
) / quantize # 除以2
) * quantize # 乘以2
然后又通过一些 numpy 的骚操作来生成每一帧的数据,然后通过 array2gif 包的 write_gif 函数来生成 gif
所以主要思路就是把整个程序完整地逆过来
由于必应没有查到 gif2array 的包,所以读取 gif 就用了经典 PIL.Image:
from PIL import Image
file = Image.open("flag.gif")
try:
while True:
gif_data.append(np.array(file))
file.seek(file.tell() + 1)
except:
print("[+] Read gif file")
然后是解决那一大段 numpy 骚操作的逆骚操作(
但是数理基础这么差的我当然是不想仔细研究了,所以直接用电波那题的 radio.mp3 带入,看一看要得到的 spectrogram 是什么样子
输出得到的 spectrogram 是:
[[-58. -48. -30. ... -58. -58. -58.]
[-58. -44. -26. ... -58. -58. -58.]
[-58. -40. -16. ... -58. -58. -58.]
...
[-58. -42. -30. ... -58. -58. -58.]
[-58. -44. -32. ... -58. -58. -58.]
[-58. -46. -34. ... -58. -58. -58.]]
[[-58. -58. -58. ... -58. -58. -58.]
[-48. -44. -40. ... -42. -44. -46.]
[-30. -26. -16. ... -30. -32. -34.]
...
[-58. -58. -58. ... -58. -58. -58.]
[-58. -58. -58. ... -58. -58. -58.]
[-58. -58. -58. ... -58. -58. -58.]]
再对应到生成的 gif 文件中,可以看出 gif 的第一帧每个矩形的高度都是 2
而第二帧每个矩形的高度也恰好是刚得出的那组数
所以要得到的 spectrogram 就是 gif 每一帧所有矩形的高度构成的矩阵的转置
再结合源码:
numpy.array([
[
red_pixel if freq % 2 and round(frame[freq // 2]) > threshold else white_pixel
for threshold in list(range(min_db, max_db + 1, quantize))[::-1]
]
for freq in range(num_freqs * 2 + 1)
])
spectrogramT = []
for data in gif_data:
res = []
for ind, line in enumerate(data.transpose()): # 将每一帧转置,方便计算
num = sum(line) # 计算每个矩形的高度(转置后是宽度)
if ind % 4 == 3:
res.append(num + min_db) # 得到的数要加上-60才符合规矩
spectrogramT.append(res)
spectrogram = np.array(spectrogramT).transpose() # 得到的结果转置一下
这样就得到了梅尔频谱图的数据,可以对 librosa 的部分进行逆过程了
翻 librosa 的文档,有 power_to_db 当然也就有 db_to_power
而且类似于 melspectrogram 函数在 librosa.feature 中,可以专门看 feature 部分的文档
翻到了 inverse 部分,可以看到有一个函数 librosa.feature.inverse.mel_to_audio 可以直接把梅尔频谱图专为音频数据,所以就用它了:
y = librosa.feature.inverse.mel_to_audio(
librosa.db_to_power(spectrogram), # 乘二除二没什么大用,而且影响效果,就删了
sample_rate, n_iter=num_freqs, # 采样率题目提供了,是 22050Hz
n_fft=fft_window_size,
hop_length=frame_step_size,
window=window_function_type,
)
这样就完成了还原,最后是输出,但是并没在 librosa 中找到音频输出的函数,所以就用了经典 soundfile:
然后打开听就行了,题目说了是个 12 位数,所以剩下的就是英语听力了,翻译过来的数字就是 flag 了
Reference¶
- Hackergame
- 国际航空无线电通讯 26 个英文字母读法 - 知乎
- LUG@USTC 官网
- Wayback Machine archive.org
- SIGBOVIK 2021
- 百度全景地图
- 伪造 http 请求 ip 地址 - 博客园
- GraphQL 官网、GraphiQL、GraphQL Voyager
- 【安全记录】玩转 GraphQL - DVGA 靶场(上)- 知乎
- librosa 文档
- PySoundFile 文档
- Wilson's theorem - wikipedia
- BUU-RSA [RoarCTF2019]babyRSA - CSDN
- Euler's totient function - wikipedia
- LUKS2 doc pdf
- 10 Linux cryptsetup Examples for LUKS Key Management
- pyinstxtractor
- uncompyle6