SCTF 2021 Writeup¶
约 347 个字 112 行代码 10 张图片 预计阅读时间 3 分钟
Abstract
这场比赛的 misc 范围比较广,有区块链有物联网还有逆向,这里就放一下三道“常规”的 misc 的 writeup 了
This_is_A_tree¶
遍历文件夹树,得到一串 base64,然后是六十四卦转 base64 然后解码
from base64 import *
import os
import string
def read(path):
return open(path, "r").read()
res = []
l = "letf/"
r = "Right/"
def readdir(path):
if os.path.isfile(path + "data"):
res.append(path + "data")
if os.path.isdir(path + l):
readdir(path + l)
if os.path.isdir(path + r):
readdir(path + r)
def get_tree():
readdir("./src/")
s = ""
for i in res:
s += read(i)
print(b64decode(s).decode())
# Chinese traditional culture is broad and profound!
# So I Want Give You My Flag But You Need Decode It.Enjoy The Flag!!:
# 师 兑 复 损 巽 震 晋 姤 大过 讼 噬嗑 震 恒 节 豫
b64table = string.ascii_uppercase + string.ascii_lowercase + string.digits + '+/'
table = {
'坤': '000000', '剥': '000001', '比': '000010', '观': '000011',
'豫': '000100', '晋': '000101', '萃': '000110', '否': '000111',
'谦': '001000', '艮': '001001', '蹇': '001010', '渐': '001011',
'小过': '001100', '旅': '001101', '咸': '001110', '遁': '001111',
'师': '010000', '蒙': '010001', '坎': '010010', '涣': '010011',
'解': '010100', '未济': '010101', '困': '010110', '讼': '010111',
'升': '011000', '蛊': '011001', '井': '011010', '巽': '011011',
'恒': '011100', '鼎': '011101', '大过': '011110', '姤': '011111',
'复': '100000', '颐': '100001', '屯': '100010', '益': '100011',
'震': '100100', '噬嗑': '100101', '随': '100110', '无妄': '100111',
'明夷': '101000', '贲': '101001', '既济': '101010', '家人': '101011',
'丰': '101100', '离': '101101', '革': '101110', '同人': '101111',
'临': '110000', '损': '110001', '节': '110010', '中孚': '110011',
'归妹': '110100', '睽': '110101', '兑': '110110', '履': '110111',
'泰': '111000', '大畜': '111001', '需': '111010', '小畜': '111011',
'大壮': '111100', '大有': '111101', '夬': '111110', '乾': '111111'
}
index = '师 兑 复 损 巽 震 晋 姤 大过 讼 噬嗑 震 恒 节 豫'.split(' ')
s = ''.join([b64table[int(table[i], base=2)] for i in index])
print(b64decode(s + '='))
# b'Ch1nA_yyds!'
fumo_xor_cli¶
发现有两帧画面是混乱的颜色,其中一帧是 a,一帧是 9
将输出重定向到文件
把里面所有的 9 都删掉,然后 cat:

得到:https://mp.weixin.qq.com/s/E_iDJBkVEC4jZanzvqnWCA
找到图片:https://imgtu.com/i/TpMSkq

图片里像素点每 9*9 一个,一共有 100*133 个点,提取出来:
from PIL import Image
img = Image.open("TpMSkq.png")
res = Image.new("RGBA", (101, 134))
width, height = img.size
print(width, height)
print(img.getpixel((800, 1000)))
for i in range(width):
for j in range(height):
if i % 9 == 1 and j % 9 == 1:
pix = img.getpixel((i, j))
res.putpixel((i // 9, j // 9), pix)
res.save("in_pix.png")

CLI 里混乱的还有一堆 9(在链接后面
from PIL import Image
import re
img = Image.new("RGBA", (101, 134))
pattern = re.compile(r'\[38;2;(\d+?);(\d+?);(\d+?)m.')
with open("fumo_a.txt", "r") as f:
for i in range(50):
line = f.readline().strip()
res = pattern.findall(line)
for j in range(133):
img.putpixel((i+50, j), tuple(int(res[j][k]) for k in range(3)))
with open("fumo_9.txt", "r") as f:
for i in range(50):
line = f.readline().strip()
res = pattern.findall(line)
for j in range(133):
img.putpixel((i, j), tuple(int(res[j][k]) for k in range(3)))
img.save("cli.png")
然后 fumo 中提出的图和 cli 提出的图 xor 得到:

没有数字,所以 flag 是:SCTF{Good_FuMo_CTF_OvO}
in_the_vaporwaves¶
听起来中间有一段感觉不太和谐,把左右声道的频谱图 xor 了一下:

发现可能中间有搞事情,又细看对比了一下左右声道的波形图,发现中间差距较大
wave 提取数据,左右声道相加:
import wave
import numpy as np
import matplotlib.pyplot as plt
wav = wave.open("c.wav", "r")
nframes = wav.getnframes()
framerate = wav.getframerate()
data = wav.readframes(nframes)
wav.close()
wave_data = np.fromstring(data, dtype=np.short)
wave_data.shape = -1, 2
wave_data = wave_data.T
time = np.arange(0, nframes) * (1.0 / framerate)
res = wave_data[0] + wave_data[1]
plt.figure()
# plt.plot(time, res)
plt.plot(time[87*framerate:128*framerate], res[87*framerate:128*framerate])
plt.show()
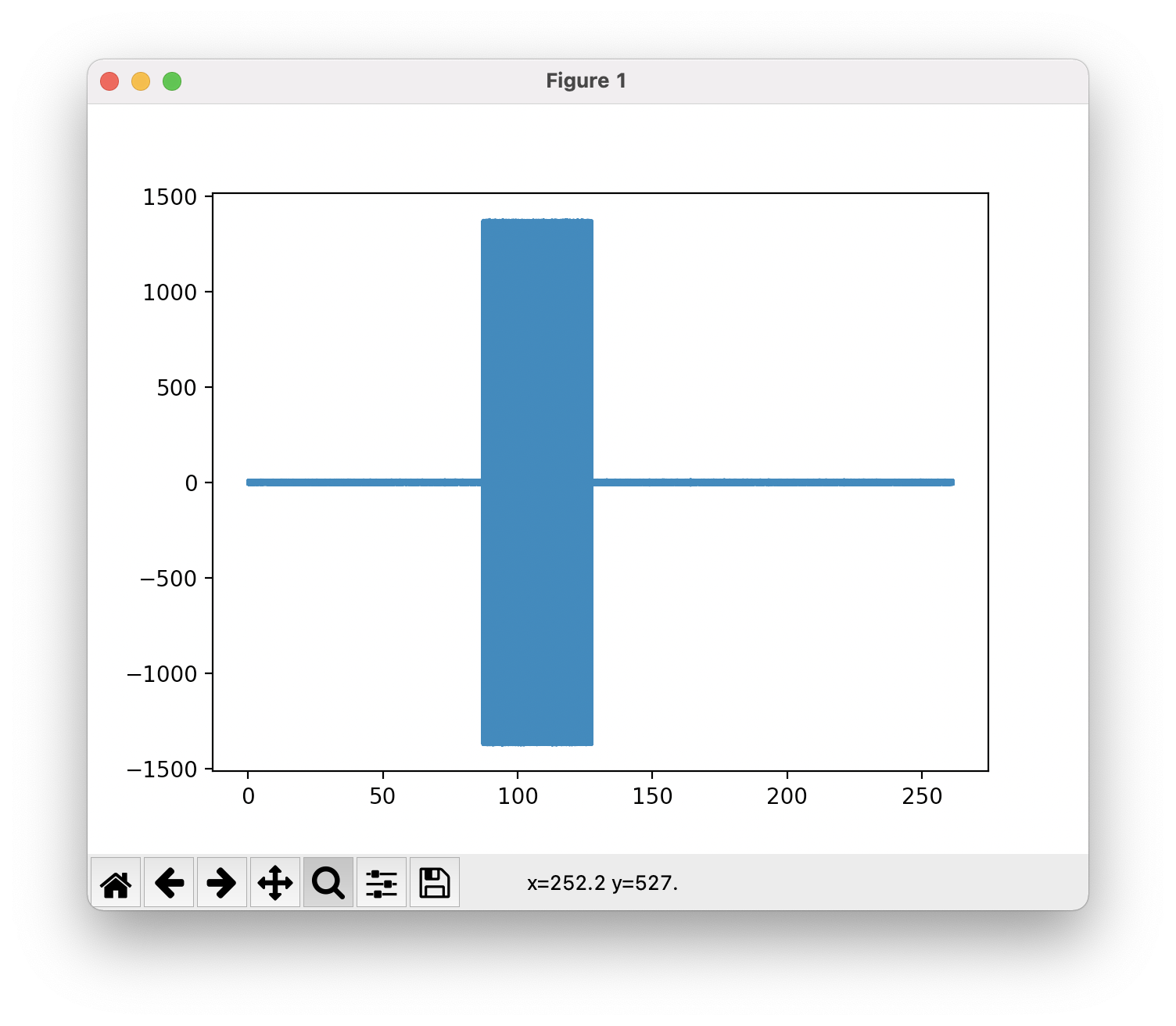
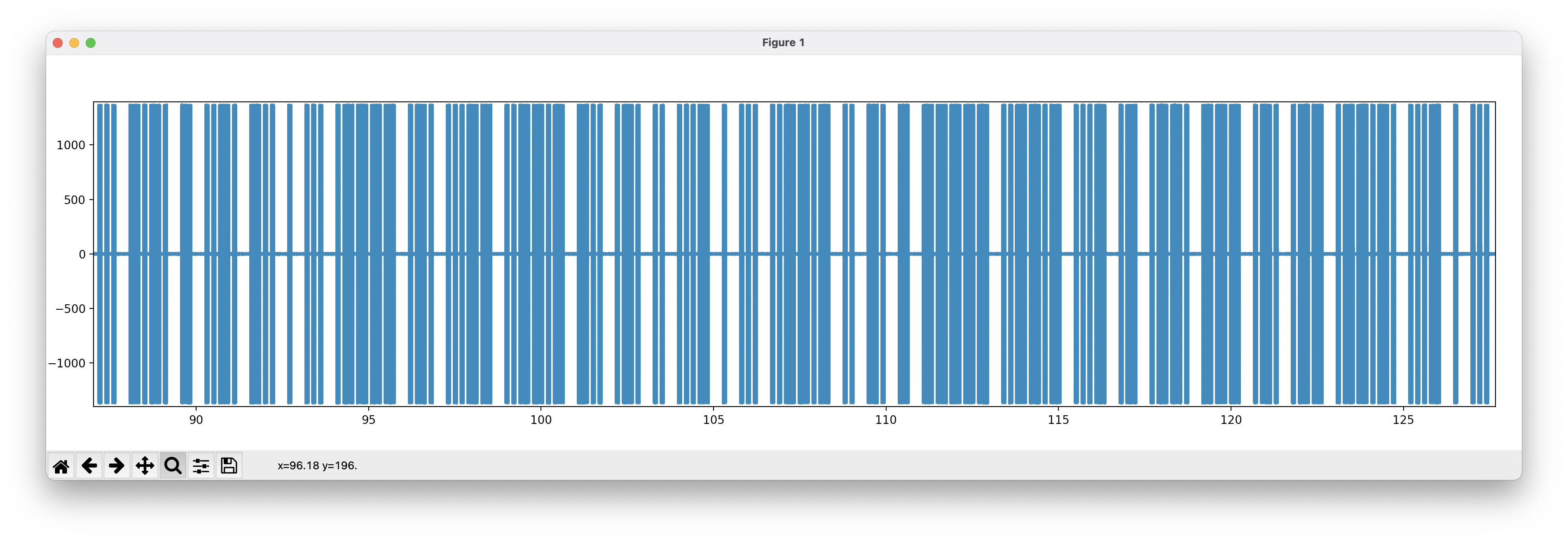
从开头三个短竖线可以推测是摩尔斯电码转换的 SCTF 开头,长短抄下来然后摩尔斯解码,得到 flag
... -.-. - ..-. -.. . ... .---- .-. ...-- ..--.- -.. .-. .. ...- . ... ..--.- .. -. - ----- ..--.- ...- .- .--. --- .-. .-- .--.-. ...- . ...
SCTFDES1R3_DRIVES_INT0_VAPORW@VES
flag: SCTF{DES1R3_DRIVES_INT0_VAPORW@VES}