TPCTF 2023 Writeup¶
约 2147 个字 398 行代码 7 张图片 预计阅读时间 12 分钟
Abstract
清北合办的 XCTF 分站赛,题不少,质量很高,队友带飞了
![]()
第一天一直在做区块链题没看别的,第二天做了俩 misc
TonysContract¶
一个没接触过的区块链,叫 TONcoin,题目给了一个公网上的合约 https://testnet.ton.cx/address/EQAM2HjRB-PFaD2mlJ5QjQAlfRAcmZ-j9ydT_54FzmbffN6E,换一个区块浏览器是 https://testnet.tonscan.org/address/EQAM2HjRB-PFaD2mlJ5QjQAlfRAcmZ-j9ydT_54FzmbffN6E。因为是公网,所以应该就不是需要发交易的,有合约字节码,所以先考虑逆向合约。
题目合约反汇编
SETCP0
(:methods
recv_internal:
2 2 BLKDROP2
c4 PUSH
CTOS
8 LDU
s1 POP
32 LDU
s0 s2 XCHG
32 PUSHINT
SDSKIPFIRST
NOW
ROT
LESS
6 THROWIF
s0 PUSH
SBITS
344 PUSHINT
EQUAL
6 THROWIFNOT
PUSHNULL
s2 PUSH
SEMPTY
NOT
<{
s0 POP
s0 s1 XCHG
LDDICT
ROTREV
}> PUSHCONT
IF
s0 s3 XCHG
CTOS
4 PUSHINT
SDSKIPFIRST
LDMSGADDR
s0 POP
s0 s1 XCHG
48 LDU
s0 s1 XCHG
92703703713403 PUSHINT
EQUAL
6 THROWIFNOT
NIL
11000385076366155543686602566826962197403024283852028545596640486225 PUSHINT
SETRAND
36 PUSHINT
PUSHREFCONT
REPEAT
s4 POP
8 LDU
s0 POP
125 EQINT
6 THROWIFNOT
35 PUSHINT
s0 PUSH
PUSHREFCONT
REPEAT
s0 POP
0 PUSHINT
36 PUSHINT
PUSHREFCONT
REPEAT
s1 s3 XCHG
s0 s1 XCHG
8 LDU
233 PUSHINT
ROT
MUL
8 PUSHPOW2
RAND
ADD
8 PUSHPOW2DEC
AND
8 PUSHPOW2
RAND
XOR
s5 PUSH
-8 PUSHINT
DICTUGET
NULLSWAPIFNOT
s0 POP
8 LDU
s0 POP
s1 s2 XCHG
TPUSH
recv_external:
s0 POP
c4 PUSH
CTOS
8 LDU
s0 s1 XCHG
0 EQINT
6 THROWIFNOT
ACCEPT
32 LDU
PUSHNULL
s1 PUSH
SEMPTY
NOT
<{
s0 POP
LDDICT
s0 s1 XCHG
}> PUSHCONT
IF
s0 s1 XCHG
288 PUSHINT
LDSLICEX
s0 POP
1 PUSHINT
NEWC
8 STU
s1 s3 XCHG
32 STU
STDICT
s0 s1 XCHG
STSLICER
ENDC
c4 POP
) 19 DICTPUSHCONST
DICTIGETJMPZ
11 THROWARG
首先简单学一下这个链,一些材料:
- 一篇 TON 合约开发入门的文章
- https://github.com/ton-blockchain
- https://github.com/ton-community
- https://docs.ton.org/develop/overview
- 官方文档入门教程 https://docs.ton.org/develop/howto/step-by-step
得到了以下信息:
- TON 中的账户不区分 ETH 一样的 EOA 和合约账户,一切皆合约
- 合约地址是 32 字节数,同时有包装了校验信息等再 base64 的 user-friendly 地址写法
- 合约采用 FunC(高级)或 Fift(低级)语言编写,编译到 TVM 字节码
- 合约部署的时候有 code 和 data 两个部分
- 都是存在链上的,code 部分是合约的字节码,data 部分是合约的数据(可修改)
- 部署方式应该类似 ETH 是通过执行 deploy bytecode 来同时部署 code 和 data(没细看)
- code、data、message 等的表示方式都是使用 bag of cells (boc) 来编码的
- https://docs.ton.org/develop/data-formats/cell-boc
- cell 是 TON 中的一个基本结构,可以存储 1023 个 bit,并且带有最多四个指向其他 cells 的 reference
- cell 的编码有点复杂,可以看链接里的示例
- cell 逐个链接形成的整体就是 bag of cells,编码就是将所有 cell 打包
- 区块浏览器解析出来的 cells 结构就是 boc 的树形结构
- 缩进代表 ref 的子节点,x{} 中的内容就是 cell 的内容
- x{} 中带有的下划线表示将最后一个 1 以及后面所有的 0 删掉(以此表示非 8 的倍数的 bit)
- message 等的规范文档里通过引入了一个新的叫 TL-B 的语言来规定(看起来好复杂好蠢)
- TVM 是一个栈式虚拟机,指令很多(类似 CISC
) ,有一个临时的栈和一些寄存器- https://docs.ton.org/learn/tvm-instructions/tvm-overview
- 栈上元素可以有类型:
- 257bit 整型、元组、Null
- cell、slice(可读的 cell
) 、builder(可写的 cell) 、continuation(一组可执行的字节码)
- 栈的初始化依次 push balance value raw_message message_body funcion_selector(internal 调用的情况)
- 寄存器 s0 就表示栈顶元素,s1 表示栈顶第二个元素,以此类推
- 其实就是别名,不是独立于栈之外的寄存器
- 有 c0-c7 八个控制寄存器:
- 其中比较重要的有 c4 初始表示合约的 data 部分,c7 初始表示一些临时数据
- https://docs.ton.org/learn/tvm-instructions/tvm-overview#control-registers
- 默认有两个函数,链上合约之间调用会触发 recv_internal,从外部调用会触发 recv_external
- 调用的时候先初始化栈和寄存器,然后执行字节码
- 字节码开头一般会读取 function_selector 判断调用的函数,然后跳转到对应的代码段(0 表示 internal,-1 表示 external)
- 这时候可以从栈上读取 message 内容,从 c4 中读取 data 部分内容
- 具体的指令可以看文档,或者文档源码 GitHub 里的 csv 表格
接下来是题目,对着字节码模拟栈逆了 external 发现其实什么都没干,所以其实主要逻辑都在 internal 中。字节码里出现了 LDDICT 指令,即从栈顶的 cell 中提取出一个 dict,但 dict 是什么、怎么解析都不太清楚,所以干脆找动调的手段了。
可以搜到 ton-community/ton-contract-executor,可以在本地不需要 TON 网络就执行一个合约,需要 yarn 装一下依赖,然后编写一个 main.mjs:
import { SmartContract, internal, externalIn } from "ton-contract-executor";
import { Cell, BitString } from "@ton/core";
async function main() {
let contract = await SmartContract.fromCell(
Cell.fromBoc(Buffer.from("...", "hex"))[0],
Cell.fromBoc(Buffer.from("...", "base64"))[0],
{debug: true}
);
const msgBody = new Cell();
console.log(msgBody);
const res = await contract.sendInternalMessage(
internal({
dest: contract.address,
value: 0n,
bounce: false,
body: msgBody,
})
)
console.log(res);
console.log(res.logs);
}
await main();
这样给合约开启 debug 之后就可以输出每次执行指令的信息,以此可以解决不知道挂在哪里以及 PUSHREFCONT 在网站上没有具体反汇编的问题。
接下来知道了运行时挂在了开头,因为开头读取的 data[1:5] 作为 timestamp 和当前的时间比较,如果在 data 设定的以前就 throw 6 异常,所以干脆在代码里把 LESS(B9) 改为 GEQ(BE) 就可以了。接下来后面的部分就可以正常执行了,根据每条指令来模拟栈,得到以下的栈变化分析:
internal 栈变化分析
msg_raw message data
msg_raw message data[8:]
msg_raw message data[8:40] data[40:]
msg_raw data[40:] data[8:40] message
msg_raw data[40:] data[8:40] message 32
msg_raw data[40:] data[8:40] message[32:] now
msg_raw data[40:] message[32:] now data[8:40]
msg_raw data[40:] message[32:] -1
msg_raw data[40:] message[32:]
msg_raw data[40:] message[32:] message[32:]
msg_raw data[40:] message[32:] 344
msg_raw data[40:] message[32:] 344 344
msg_raw data[40:] message[32:] 0
msg_raw data[40:] message[32:] null
msg_raw data[40:] message[32:] null 1
msg_raw data[40:] message[32:] null 1 cont1
msg_raw data[40:] message[:32] null
msg_raw data[40:] message[:32]
msg_raw message[32:] data[40:]
msg_raw message[32:] D data[40+dict:]
msg_raw data[40+dict:] message[32:] D
D data[40+dict:] message[32:] msg_raw
D data[40+dict:] message[32:] msg_raw 4
D data[40+dict:] message[32:] msg_raw[4:]
D data[40+dict:] message[32:] msg_raw.src msg_raw[src:]
D data[40+dict:] message[32:] msg_raw.src
D data[40+dict:] msg_raw.src message[32:]
D data[40+dict:] msg_raw.src message[32:32+48] message[32+48:]
D data[40+dict:] msg_raw.src message[32+48:] message[32:32+48]
D data[40+dict:] msg_raw.src message[32+48:] message[32:32+48] 92703703713403
D data[40+dict:] msg_raw.src message[32+48:]
D data[40+dict:] msg_raw.src message[32+48:] ()
D data[40+dict:] msg_raw.src message[32+48:] () 11000385076366155543686602566826962197403024283852028545596640486225
D data[40+dict:] msg_raw.src message[32+48:] ()
D data[40+dict:] msg_raw.src message[32+48:] () 36
D data[40+dict:] msg_raw.src message[32+48:] () 36 refcont
D data[40+dict:] msg_raw.src message[32+48:] ()
D data[40+dict:] msg_raw.src () message[32+48:]
D data[40+dict:] msg_raw.src () message[32+48:32+56] message[32+56:]
D data[40+dict:] msg_raw.src () message[32+48:32+56] message[32+56:] 233
D data[40+dict:] msg_raw.src () message[32+56:] 233 message[32+48:32+56]
D data[40+dict:] msg_raw.src () message[32+56:] 233*message[32+48:32+56]
D data[40+dict:] msg_raw.src () message[32+56:] 233*message[32+48:32+56] 256
D data[40+dict:] msg_raw.src () message[32+56:] 233*message[32+48:32+56] rand(256)
D data[40+dict:] msg_raw.src () message[32+56:] 233*message[32+48:32+56]+rand(256)
D data[40+dict:] msg_raw.src () message[32+56:] 233*message[32+48:32+56]+rand(256) 255
D data[40+dict:] msg_raw.src () message[32+56:] (233*message[32+48:32+56]+rand(256))&(255)
D data[40+dict:] msg_raw.src () message[32+56:] (233*message[32+48:32+56]+rand(256))&(255) rand(256)
D data[40+dict:] msg_raw.src () message[32+56:] ((233*message[32+48:32+56]+rand(256))&255)^rand(256)
D data[40+dict:] msg_raw.src () message[32+56:] ((233*message[32+48:32+56]+rand(256))&255)^rand(256) D
D data[40+dict:] msg_raw.src () message[32+56:] ((233*message[32+48:32+56]+rand(256))&255)^rand(256) D 8
D data[40+dict:] msg_raw.src () message[32+56:] D[((233*message[32+48:32+56]+rand(256))&255)^rand(256)] ?
D data[40+dict:] msg_raw.src () message[32+56:] D[((233*message[32+48:32+56]+rand(256))&255)^rand(256)][:8] D[((233*message[32+48:32+56]+rand(256))&255)^rand(256)][8:]
D data[40+dict:] msg_raw.src () message[32+56:] D[((233*message[32+48:32+56]+rand(256))&255)^rand(256)][:8]
D data[40+dict:] msg_raw.src message[32+56:] () D[((233*message[32+48:32+56]+rand(256))&255)^rand(256)][:8]
D data[40+dict:] msg_raw.src message[32+56:] (D[((233*message[32+48:32+56]+rand(256))&255)^rand(256)][:8])
... exec refcont for 36 times ...
D data[40+dict:] msg_raw.src message[...:] flag_content
flag_content data[40+dict:] msg_raw.src message[...:]
...
flag_content data[40+dict:] msg_raw.src 35
flag_content data[40+dict:] msg_raw.src 35 35
flag_content data[40+dict:] msg_raw.src 35 35 refcont
flag_content data[40+dict:] msg_raw.src 35
flag_content data[40+dict:] msg_raw.src 35 35
flag_content data[40+dict:] msg_raw.src 35 36
flag_content data[40+dict:] msg_raw.src 35 rand(36)
flag_content data[40+dict:] msg_raw.src 35 rand(36) flag_content 35
flag_content data[40+dict:] msg_raw.src 35 rand(36) flag_content[35]
flag_content data[40+dict:] msg_raw.src 35 rand(36) flag_content[35] (flag_content) rand(36)
flag_content data[40+dict:] msg_raw.src 35 rand(36) flag_content[35] flag_content[rand(36)]
flag_content[35] data[40+dict:] msg_raw.src 35 rand(36) flag_content flag_content[rand(36)] 35
flag_content[35] data[40+dict:] msg_raw.src 35 rand(36) flag_content{35=flag_content[rand(36)]}
35 data[40+dict:] msg_raw.src flag_content{35=flag_content[rand(36)]} flag_content[35] rand(36)
35 data[40+dict:] msg_raw.src flag_content{35=flag_content[rand(36)], rand(36)=flag_content[35]}
flag_content{35=flag_content[rand(36)], rand(36)=flag_content[35]} data[40+dict:] msg_raw.src 35
flag_content{35=flag_content[rand(36)], rand(36)=flag_content[35]} data[40+dict:] msg_raw.src 34
flag_content_modified data[40+dict:] msg_raw.src 34
flag_content_modified data[40+dict:] msg_raw.src 34 34
flag_content_modified data[40+dict:] msg_raw.src 34 35
flag_content_modified data[40+dict:] msg_raw.src 34 rand(35)
flag_content_modified data[40+dict:] msg_raw.src 34 rand(35) flag_content_modified 34
...
flag_content_modified data[40+dict:] msg_raw.src 0
flag_content_modified data[40+dict:] msg_raw.src
flag_content_modified data[40+dict:] msg_raw.src 0
flag_content_modified data[40+dict:] msg_raw.src 0 36
flag_content_modified data[40+dict:] msg_raw.src 0 36 refcont
flag_content_modified data[40+dict:] msg_raw.src 0
flag_content_modified data[40+dict:] msg_raw.src 0 flag_content_modified 0
flag_content_modified data[40+dict:] msg_raw.src 0 flag_content_modified[0]
flag_content_modified flag_content_modified[0] msg_raw.src 0 data[40+dict:]
flag_content_modified flag_content_modified[0] msg_raw.src 0 data[40+dict:48+dict] data[48+dict:]
flag_content_modified data[48+dict:] msg_raw.src 0 flag_content_modified[0] data[40+dict:48+dict]
flag_content_modified[0]==data[40+dict:48+dict]?
这样看整体的逻辑就是:
input = input[4:]
if input[:6] != "TPCTF{":
throw 6
flag = []
setrand(11000385076366155543686602566826962197403024283852028545596640486225)
for i in range(36):
flag.append(D[((233*input[i]+rand(256))&255)^rand(256)][0])
for i in range(35, 0, -1):
a = rand(i + 1)
flag[i], flag[a] = flag[a], flag[i]
for i in range(36):
if flag[i] != data_after_dict[i]:
throw 666
为了拿到其中的数据需要让 executor 在运行中输出栈的内容,通过阅读代码知道 ton-contract-executor 最终调用了 ton 官方 vm-exec 分支里编译好的 wasm 来跑指令,同时也给了 builder ton-community/ton-vm-exec-builder(这个 builder 的 README 有问题,clone ton 源码的时候需要加 --recursive
这样就可以拿到其中出现的所有值了,不过最后的判断只要有不一样的就会抛出 666 结束执行而不显示后面的 data_after_dict 值,所以为了 dump 出这部分还需要 patch 一下 contops.cpp 里 exec_throw_fixed,使得 excno 为 666 时 return 0。之后得到所有栈输出,根据正则 (\d+?) (\d+?) CS 可以筛选得到 data_after_dict 的内容,根据正则 execute RAND.*?(\d+?) (\d+?) \] 可以筛选得到每次交换的 i 和 a,然后反过来交换回去得到第一个循环后的 flag:
[46, 254, 159, 162, 180, 48, 104, 193, 90, 2, 82, 236, 188, 10, 224, 196, 138, 170, 62, 151, 172, 27, 4, 209, 58, 16, 27, 88, 32, 46, 161, 174, 86, 193, 135, 101]
第一个循环里的运算比较复杂而且有截断,还有 D 字典的结构也不太了解。因为每一位的计算和其他位都没有关系,所以选择从前往后的方法,逐位爆破 flag:
爆破脚本
import os
import re
from tqdm import trange
target = [46, 254, 159, 162, 180, 48, 104, 193, 90, 2, 82, 236, 188, 10, 224, 196, 138, 170, 62, 151, 172, 27, 4, 209, 58, 16, 27, 88, 32, 46, 161, 174, 86, 193, 135, 101]
template = "4141414154504354467b%s7d"
flag = [0x41] * 36
for i in range(36):
for j in trange(32, 127):
flag[i] = j
# logs = os.popen("node debug.mjs %02x" % j).read() # 65536 长度限制
os.system("node debug.mjs %s > tmp" % (template % bytes(flag).hex()))
with open('tmp', 'r') as f:
logs = f.read()
res = re.findall(r"..376; refs: 0..0\} (\d+?) CS\{Cell\{000", logs)
if int(res[i]) == target[i]:
print(bytes(flag))
break
import { SmartContract, internal, externalIn } from "ton-contract-executor";
import { Cell, BitString } from "@ton/core";
async function main() {
let contract = await SmartContract.fromCell(
Cell.fromBoc(Buffer.from("te6cckECCAEAATgAART/APSkE/S88sgLAQIBIAIDBPjSbCLtRNDTBzHTHwKAINch+CNYufJGINdJgQFYuvKGbSLHALOVMAH0BFneA9B01yH6QDAB0y8BgiBUUENURnu68oZvAILQaHR0cHM6Ly95b3V0dS5iZS9kUXc0dzlXZ1hjUfgUgCSK5DTTBzDAffKGgCMgiuQwcIAkiuQTBAUGBwBi8jDtRNDTBwHAAPKG+ADTH20hxwCzlDD0BAHeAYEBINcYMHHIywcTyx/0AAHPFsntVABEAdMHgQDpWKiDB/gRoIQHsIMH+BGyJXj0Dm+hMNMHMBJvjAAuIKT4EVNBb4FTUW+BVBYDb4VAVW+FA6UAHFMwb4ED0wdQRLry4pqkAERfA3AggBjIywVQA88WgQKa+gISy2rLH4szY2NozxbJc/sAUXUrEg==", "base64"))[0], // patched
Cell.fromBoc(Buffer.from("...", "hex"))[0], // not changed
{debug: true}
);
let bf_content = process.argv[2];
const msgBody = new Cell({bits: new BitString(Buffer.from(bf_content, "hex"), 0, 47 * 8)});
const res = await contract.sendInternalMessage(
internal({
dest: contract.address,
value: 0n,
bounce: false,
body: msgBody,
})
);
console.log(res.logs);
}
await main();
process.exit();
这样爆破出来就能得到一个 uuid 就是 flag。
wait for first blood¶
很有意思的形式,一个二维码隔一段时间多给出几个点,直到一血后不再增加。
第二天晚上才可做,已知版本 v7,格式信息可以完全纠错,等级 H 掩码 0,且注意 v7H 下 data codewords 和 error correction codewords 会进行分组重排,前四组每组 13 数据 26 纠错,最后一组 14 数据 26 纠错,解读二维码比特流再重排回来得到正常的序列为(不是最新
?010000?0??0101000101?000000?100?1?010?0?11010?001000?000?001001?000001111?11?0?1101000000100?0010111?011001110110100?01?10?110?11?100001011100??001110?1?100100100000100001?100101?10?010?01000111101?0?1?01000100111011?101?00111000100?11???111011?0110001100011010?0010000001?001?101100010001101100110?1000110010?00?1011?011?0?1000111000001101010011?001?011001100?1011?0110?01?011001100011001100110??0?01?0101?011000101100101?01110000?10?00?001101100??10101?11000??0011000?0?1000?10011?0010011100100110101?0110?0101?00??001100?100
然后根据二维码的编码进行解读,开头是 HttPS://gist.giTHUB.COM/KONANO/ 可以完全确定,后面 32 个字节在 [0-9a-f] 间,可以基本缩小范围:
人工解码
0010
000000001 - len = 1
010001 - H
0100
00000010 - len = 2
01110100 - t
01110100 - t
0010
000000100 - len = 4
10010000001 - PS
11111100111 - :/
0100
00001000 - len = 8
00101111 - /
01100111 - g
01101001 - i
01110011 - s
01110100 - t
00101110 - .
01100111 - g
01101001 - i
0010
000010000 - len = 16
10100101010 - TH
10101010001 - UB
11101101110 - .C
10001001110 - OM
11110100011 - /K
10001001111 - ON
00111011001 - AN
10001100011 - O/
0100
00100000 - len = 32
01100101 - e
01100010 - b
00110110 - 6
01100100 - d
0110010? - d/e
00110110 - 6
01100010 - b
00111000 - 8
00110101 - 5
0011?001 - 1/9
00110011 - 3
00110111 - 7
0110001? - b/c
01100110 - f
00110011 - 3
00110??0 - 0/2/4/6
00110101 - 5
00110001 - 1
01100101 - e
00111000 - 8
01100001 - a
00110110 - 6
00110101 - 5
011000?? - a/b/c
0011000? - 0/1
011000?1 - a/c
0011?001 - 1/9
00111001 - 9
00110101 - 5
00110?01 - 1/5
01100010 - b
01100?10 - b/f
0
然后全排列枚举未知比特,合法的 url 就进行访问,正确的 200 不正确 404,可以爆破。
爆破代码
total = "".join(known)
import itertools
from tqdm import tqdm
import requests
for i in tqdm(itertools.product("01", repeat=unknown_bits), total=2**unknown_bits):
flag =
cur = total[:]
for j in range(unknown_bits):
cur = cur.replace('?', i[j], 1)
res = "".join([chr(int(cur[i:i+8], 2)) for i in range(0, len(cur), 8)])
for each in res:
if each not in "0123456789abcdef":
flag = 1
break
if flag == 1:
continue
url = "https://gist.github.com/Konano/" + res
r = requests.get(url)
if r.status_code == 200:
print(url)
print(res)
break
爆破得到 https://gist.github.com/Konano/eb6dd6b85937bf3651e8a65c1a9951bb,访问得到 flag: TPCTF{WhEN_nAnO_MEeTS_qrcod3_1n_thE_Mix_OF_jEop@rdy_@nd_k0h(?)}。
其实可以枚举之后按照 v7 H0 重新生成一个新的二维码再和题目的比较验证就可以了,本地爆破效率更高,本应该更早做出来,痛失三血。
小 T 的日常 ¶
题目
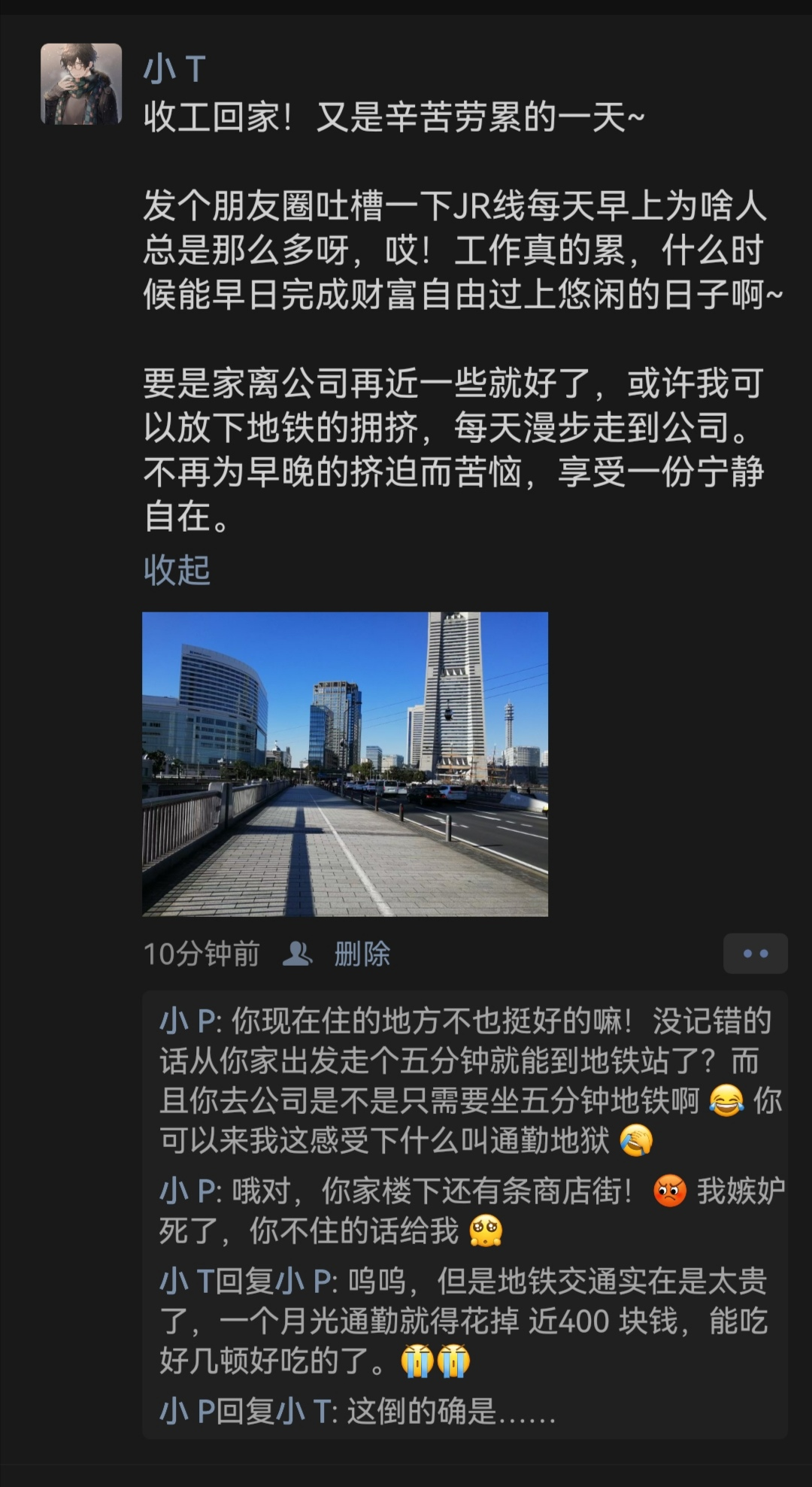
本题 flag 的正则表达式为 TPCTF{[A-Z]+:\d+},其中 [A-Z]+ 为小 T 家楼下商店街的一元店隔壁的服装店店名,\d+ 为这家服装店的电话号码。
Google 搜索图片可以查到这里是横滨的樱木町和车马道两个地铁站附近,应该是上班地点,所以接下来要根据通勤信息找到居住地点。
五分钟路程一个月 8000 日元的话,可能是 JR 可能是樱木町到石川町(150*2*26=7800
如果不是 JR 的话有可能是营蓝线樱木町到阪东桥(200*2*20=8000

所以 flag 为 TPCTF{NARUKIYA:2311855}
(其实队友做的时候是当成元町中华街理解的,然后顺着这条路一直爬找百元店看街景,歪打正着找到了 NARUKIYA)